这大概是我读过关于AI大模型最全面、好读又易懂的文章了

推开AI的门,你是站在门外怕迟到的人。很多人害怕迟到,害怕在众目睽睽之下,被视作一个犯错的学生。就如同,AI”呼的一下”就来了,并且发展迅猛,很多人也怕被它甩在后面,而我就是其中之一。
本文旨在为读者勾勒出大语言模型的大致轮廓。文章从神经网络的基石讲起,逐步深入至大模型的推理、训练,并分享了AI浪潮下对基础设施的新要求,最后简单介绍了人们如何使用大模型。
1. 你有没有想过
当第一次体验到大模型带给你的惊喜时,你有没有想过,它到底是怎么思考的?你或许忙碌、疲惫,连思考”它是怎么思考的”都来不及去思考。
可是在过去的很长时间里,模型参数、token、向量化、蒸馏、温度系数等层出不穷的新概念,不断地融入你的工作和生活,你也许已经习以为常,日用而不知。
我也时常在想:大模型的 “思考” 过程,和这些概念到底有着怎样的关联?有没有一条清晰的主线,能把这些零散的知识点串联起来?
答案……其实就在我们常听到的神经网络里。神经网络既是大模型的思考”内核”和”骨架”,又是大语言模型的核心思想来源。
2. 即便是十几年后
即便是十几年后的今天,我也会时常记起,曾经教过我的一位计算机老师。在一次课堂上,他抛出了一个让我耳目一新的概念——神经网络。然而他对此却颇有微词,认为人类在连神经是怎么回事儿都没搞明白的情况下,提出这个理论就是故弄玄虚。
直到参加工作后,随着阅历的增长,我逐步地发现,面对新事物,我的态度逐步从”故弄玄虚”转变为”先学习看看”。当然,让我下决心研究神经网络的原因,远不止于此。更为关键是,“神经网络”这四个字里面藏着”网络”两个字。在网络这个行当从业多年,职业的惯性,让我对这两个字极为敏感。
3. 既不是神经也不是网络
3.1 输入层、隐藏层、输出层
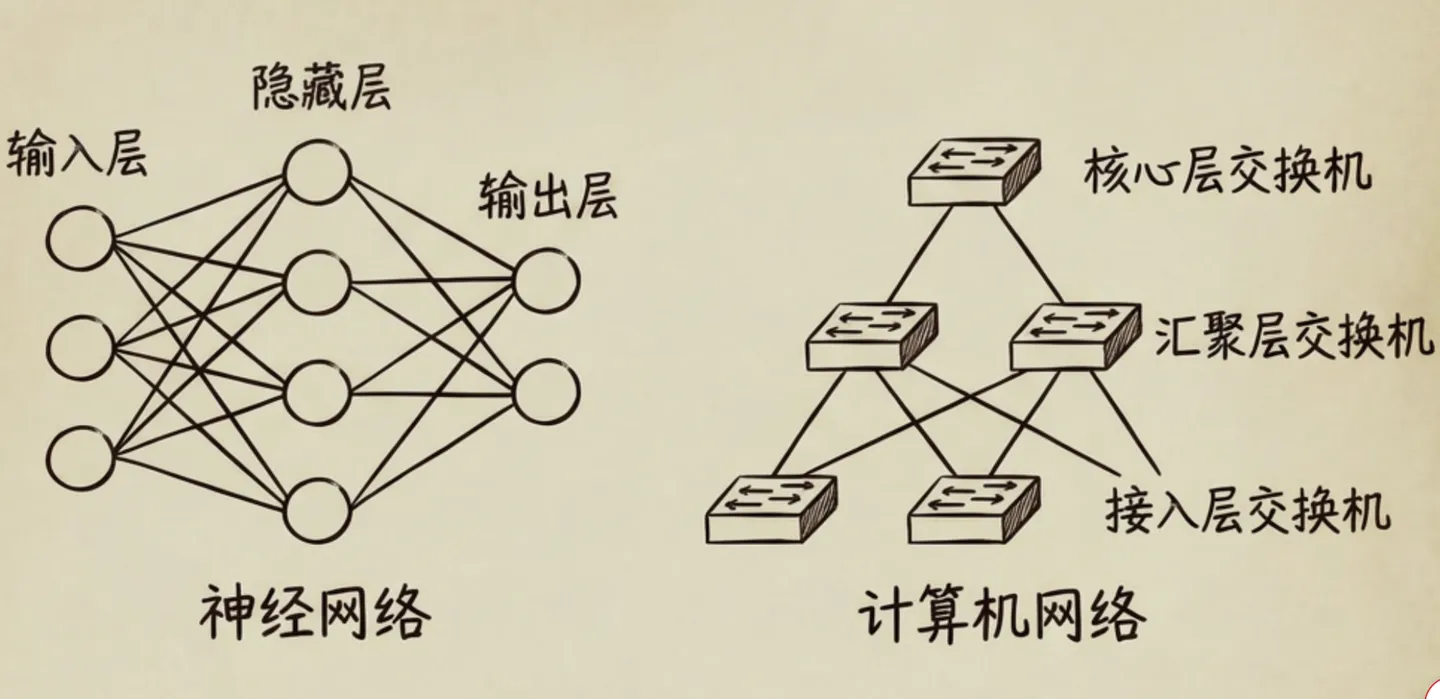
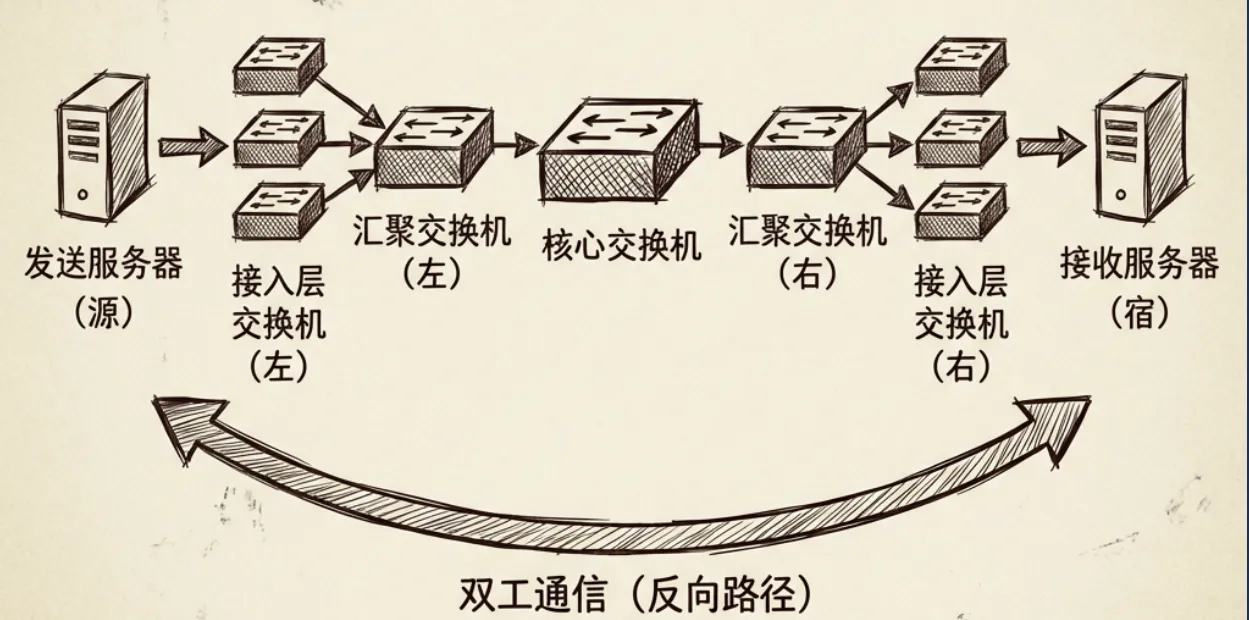
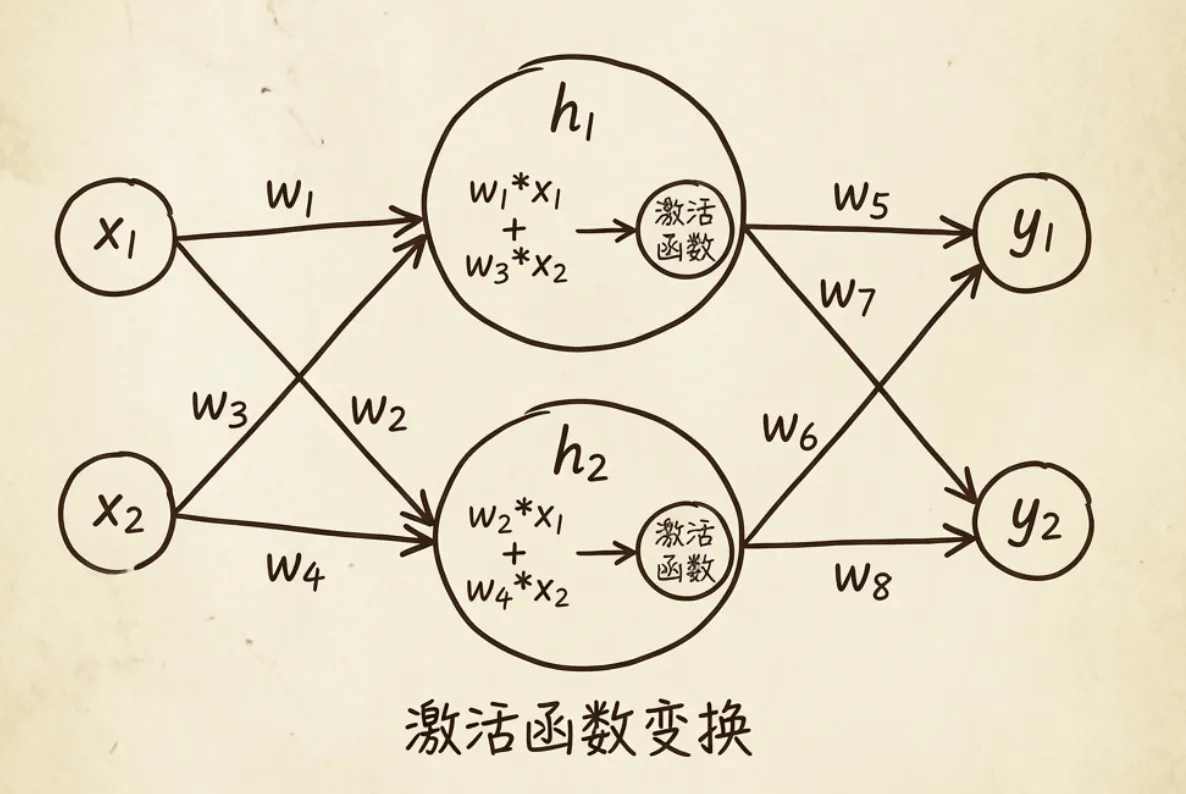
神经网络之所以叫网络,单纯从它的长相来看,它确确实实是由不同的层组成,每一层又有多个不同的节点,相邻层之间的节点进行了全互联,看着就像是一张”网”。
如果把发送流量的服务器A作为信息输入,把接收流量的服务器B作为信息输出,那么:
- 输入层:服务器A上联的接入层网络交换机
- 输出层:服务器B上联的接入层网络交换机
- 隐藏层:位于输入层与输出层之间的这些层
3.2 正向传播
在神经网络中,人们把信号从输入层,逐层经过隐藏层后,传递到输出层的过程,称为正向传播(也称前馈)。
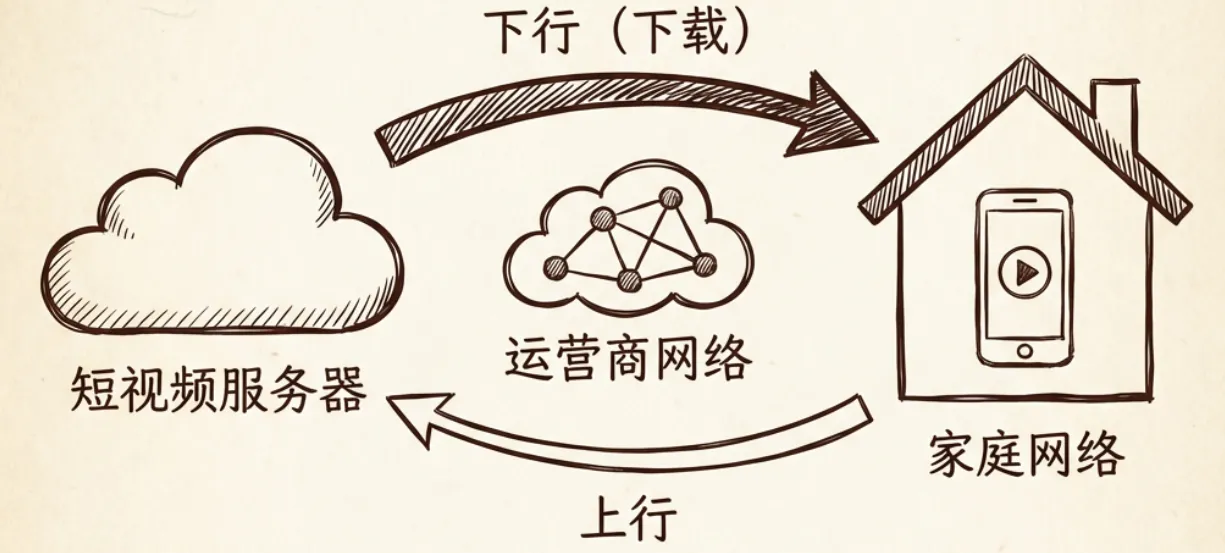
神经网络严格规定了输入层就是输入层,它永远不可能变成输出层。并且信号只能从输入层单向传递到输出层。这就像运营商网络中的上行带宽和下行带宽,有着严格的方向性。
3.3 神经元
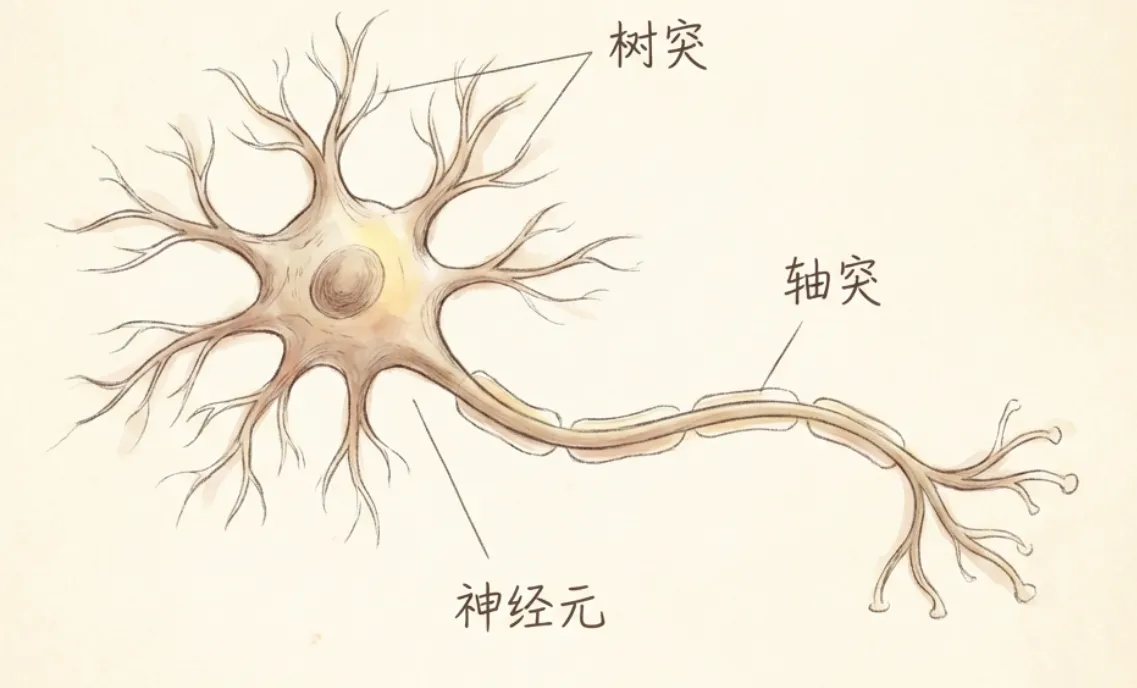
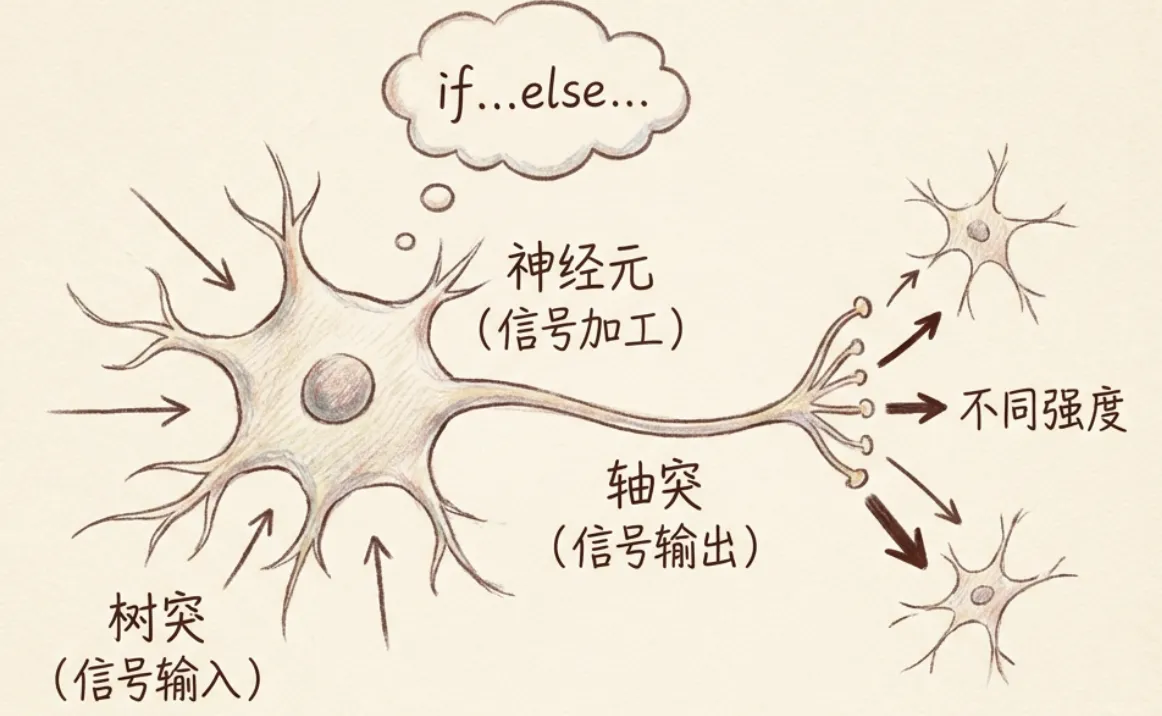
神经网络之所以叫神经网络,因为它确确实实发源于人体神经这个学科。大脑神经元上有两类”东西”:
- 树突:可以接收信号,像树的根须一样,用来感知人间冷暖
- 轴突:用来连接其他的神经元,传递信号
大脑神经元也有着不同的分工:
- 感觉神经元:负责接收信号(对应输入层)
- 联络神经元:负责传递信号(对应隐藏层)
- 运动神经元:负责输出信号(对应输出层)

3.4 线性与非线性
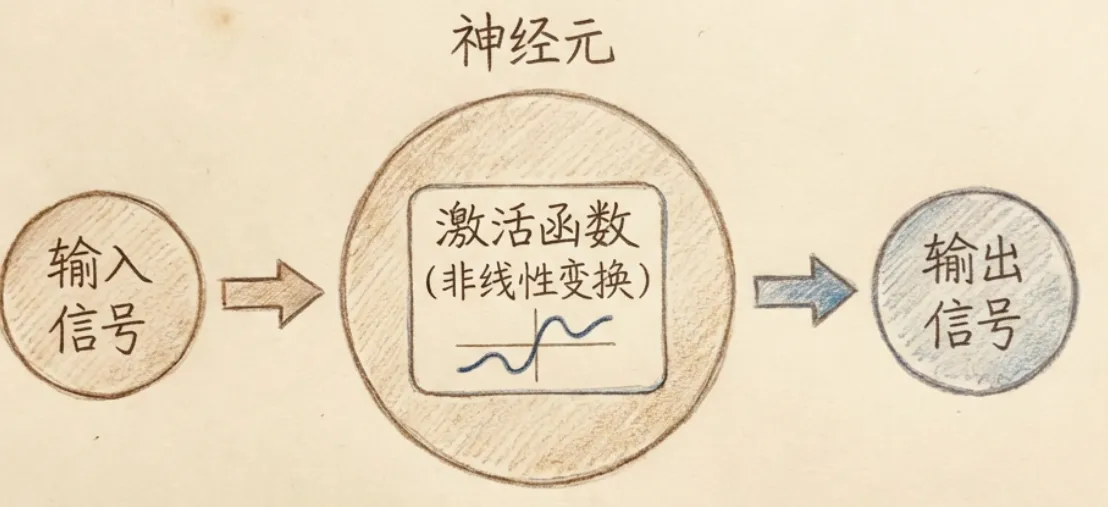
大脑神经元从树突收集到信号后,并不是直接交给轴突传递给其他神经元。神经元有很大的自由度,当它收到信号后,可以自由选择输出或者不输出给下一个神经元。即便是它选择输出,输出的信号强度也是不一样的。
神经网络中神经元对于信号输入,也要经过层层加工。执行非线性变换的”工具”就被称为激活函数。
3.5 激活函数与激活
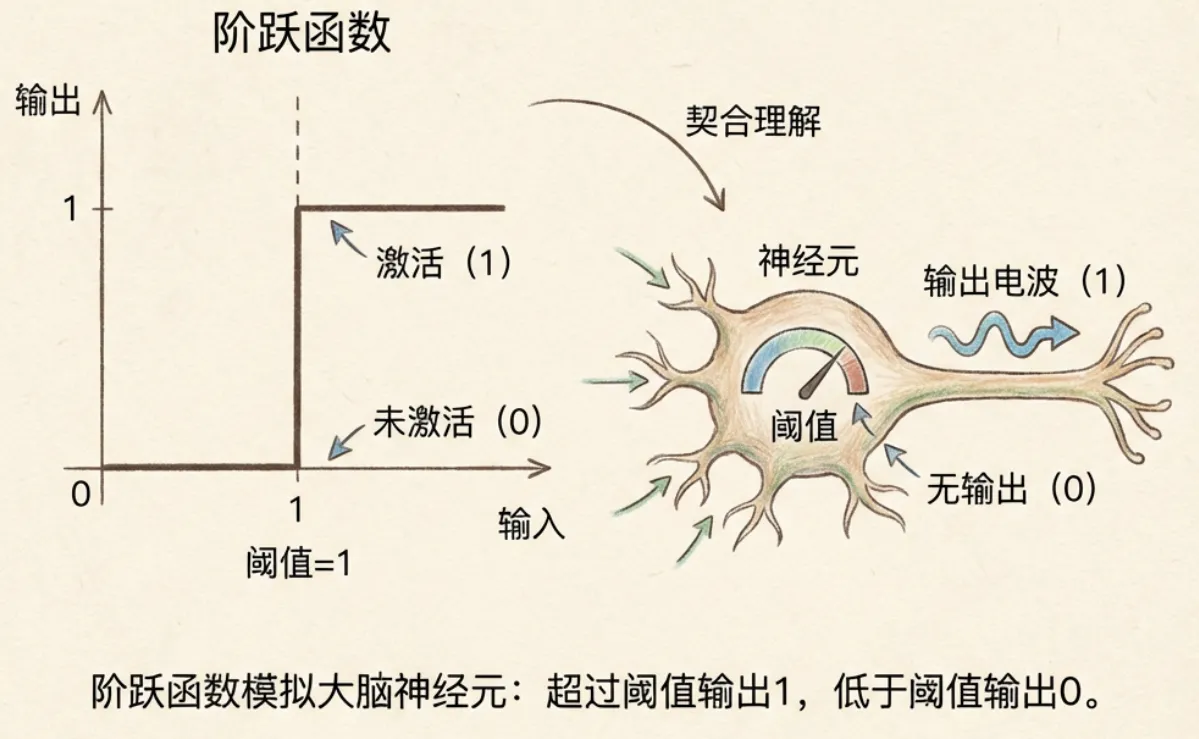
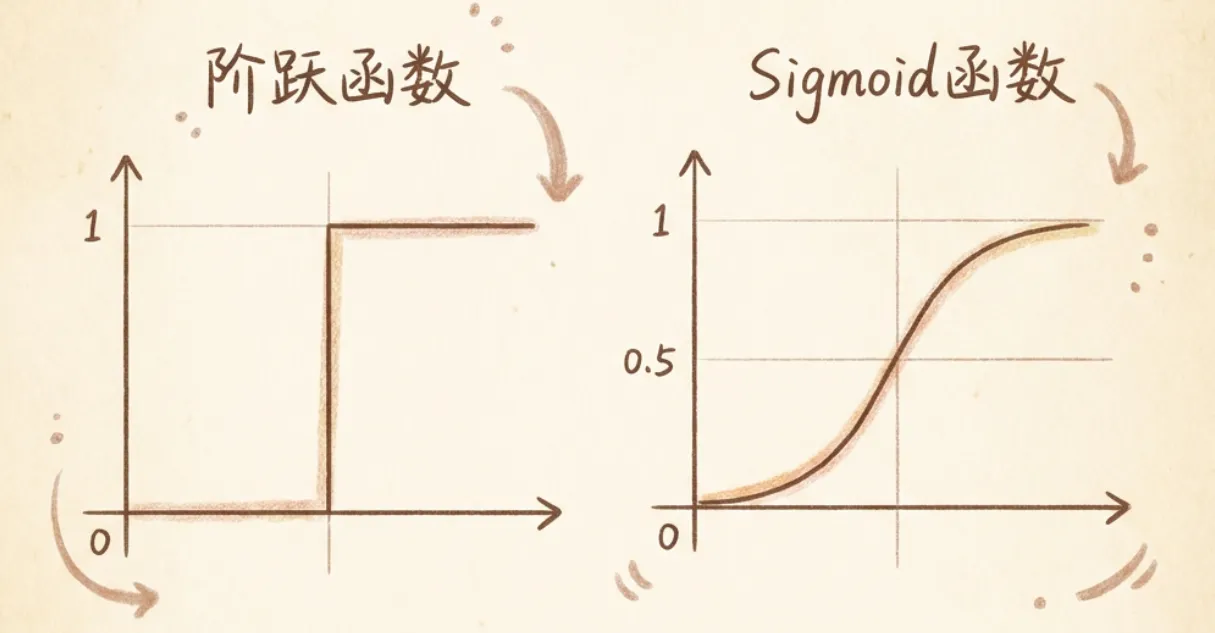
激活函数的目的就是进行非线性变换,来模拟大脑神经元。之所以叫”激活”,是因为人类发现并不是任意的信号进入大脑神经元都可以转换成输出的,而是仅仅达到某个阈值后才能转换成有效输出。
最早使用的激活函数是阶跃函数,输入信号经过变换后,只会输出0或者1。后来人们采用了Sigmoid函数,可以输出0-1之间任意的连续数值,能够精准表达神经元的’激活强度’。
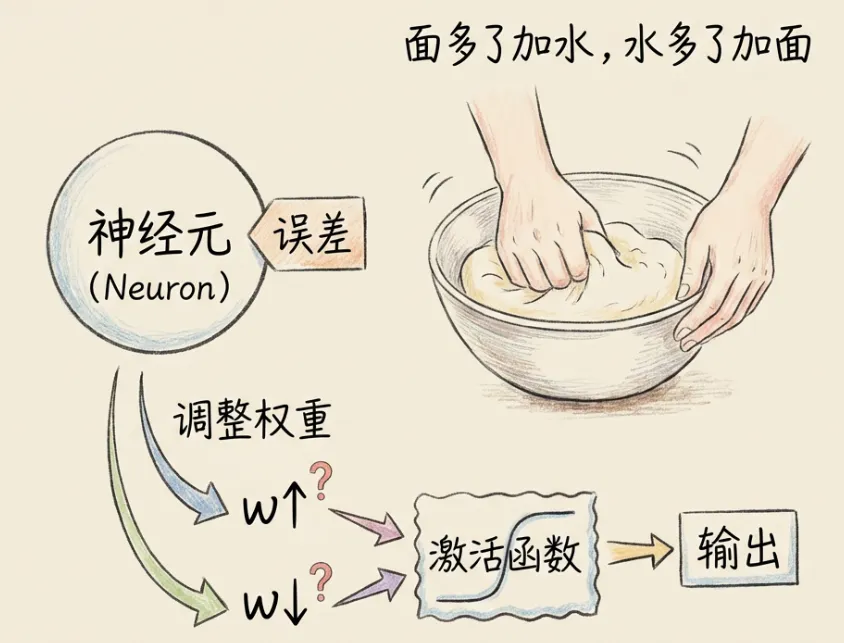
3.6 权重和偏置
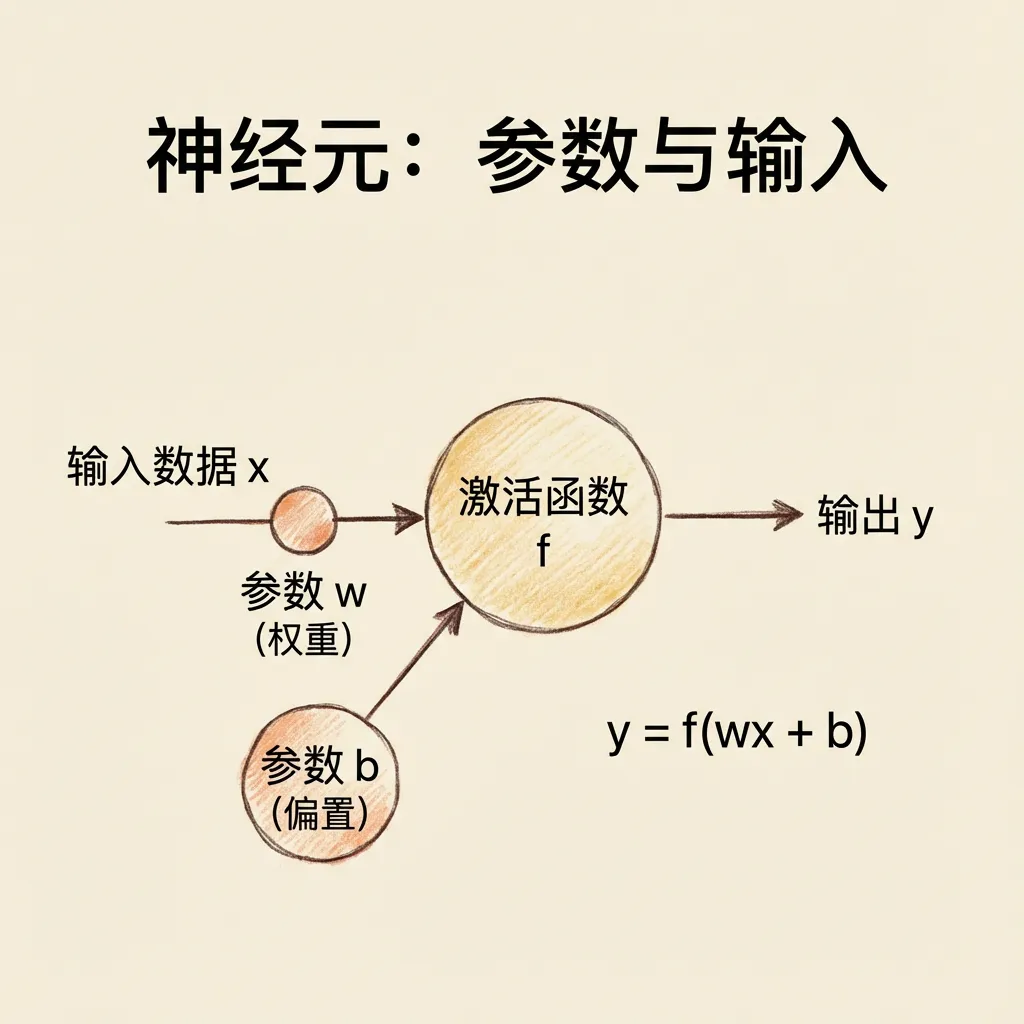
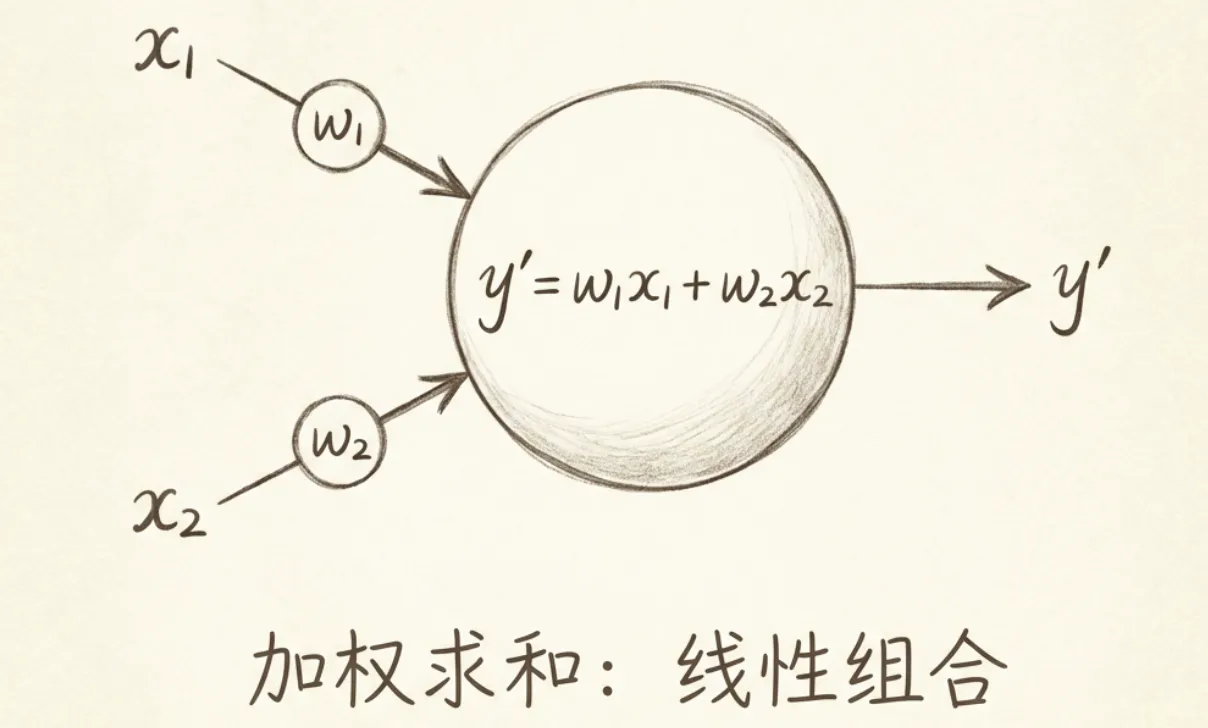
神经网络中的神经元,会为不同的输入分配不同的权重(用w表示)。神经元将不同输入用权重加权求和后,还要和阈值进行比对,才能代入激活函数。
偏置(b)的作用是用来表示神经元被激活的难易程度。神经元从输入到输出的完整公式:
y = f(wx + b)其中:y表示输出,f表示激活函数,w表示权重,x表示输入,b表示偏置。
3.7 神经网络的参数
权重和偏置是组成神经网络最基本的参数。如果一个神经网络有很多层、每一层节点很多,那么权重数量就会增加到惊人的规模。例如:
- GPT-3 的参数规模:1750亿
- Deepseek V3.2 的参数规模:超过6700亿
3.8 权重与参数、变量、数据
模型文件的主体就是参数。神经网络输出的数值,都会被映射到词表里面的词,转换成人类能看懂的文字。
参数本质上是”被不断调优的常量”,一旦训练结束、模型固化,这些参数就会固定下来。而真正的变量指的是模型接收的输入数据。
4. 神经网络的学习
4.1 神经网络与矩阵运算
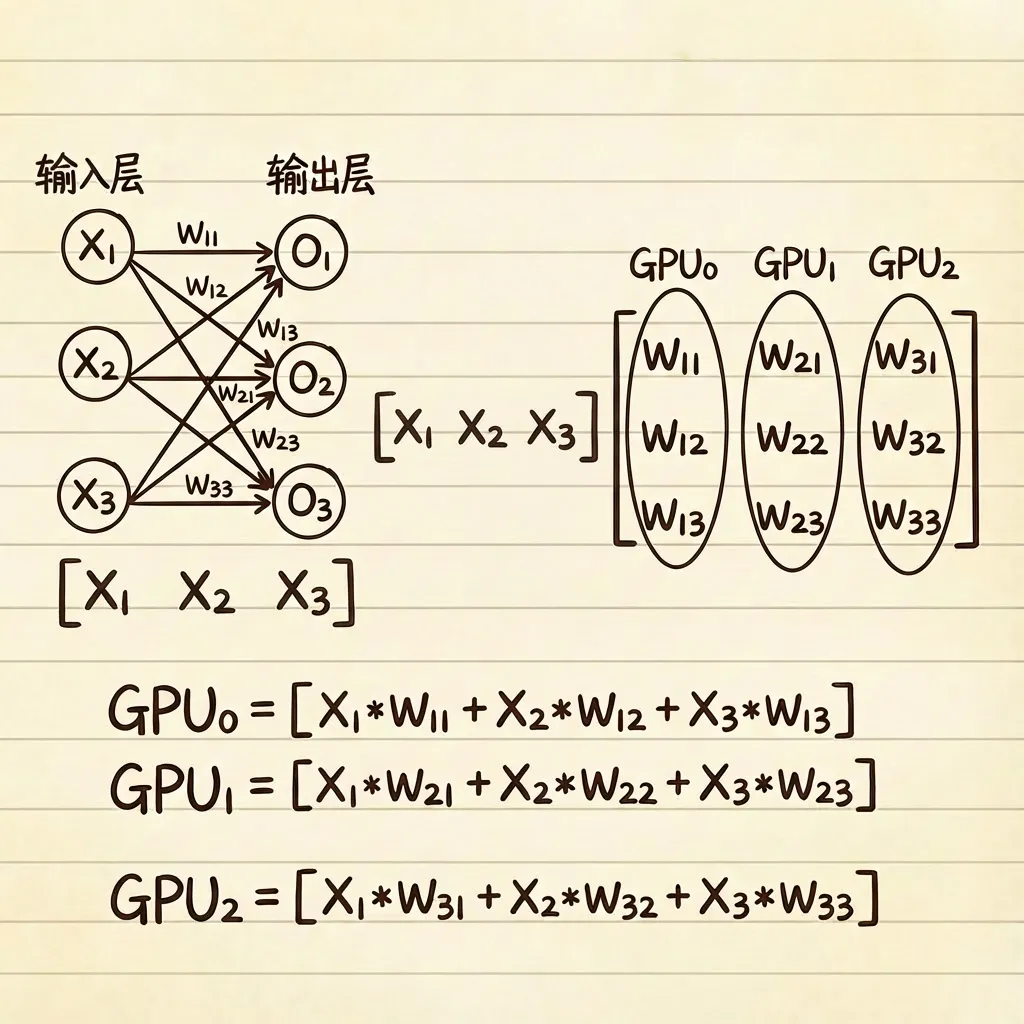
神经网络正向传播的过程,本质上就是多个不同矩阵按序相乘的过程。我们要做的仅仅是把这些权重矩阵分发给GPU进行并行计算。
4.2 预测值、目标值、神经网络学习
- 预测值:神经网络的输出
- 目标值:预设的参考值
- 神经网络学习:不断尝试更新权重和偏置,缩小与目标的差距
这个学习不是自主进行的,而是被人工标记的”目标值”监督进行的。
4.3 照进神经网络的光
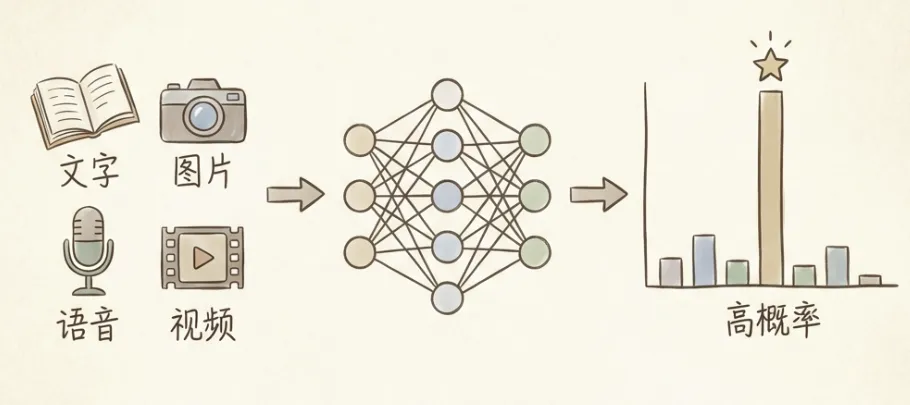
文字、图片等现实信息需要被数字化后才能输入神经网络。这个过程就是将信息转换为数字向量。
4.4 损失函数
预测值与目标值之间存在的差额,称为误差或者损失。为了解决正负误差相互抵消的问题,人们使用:
- 绝对值函数:去掉误差的负号
- 平方函数:取消误差的符号
- 交叉熵函数:现代大语言模型常用的损失函数
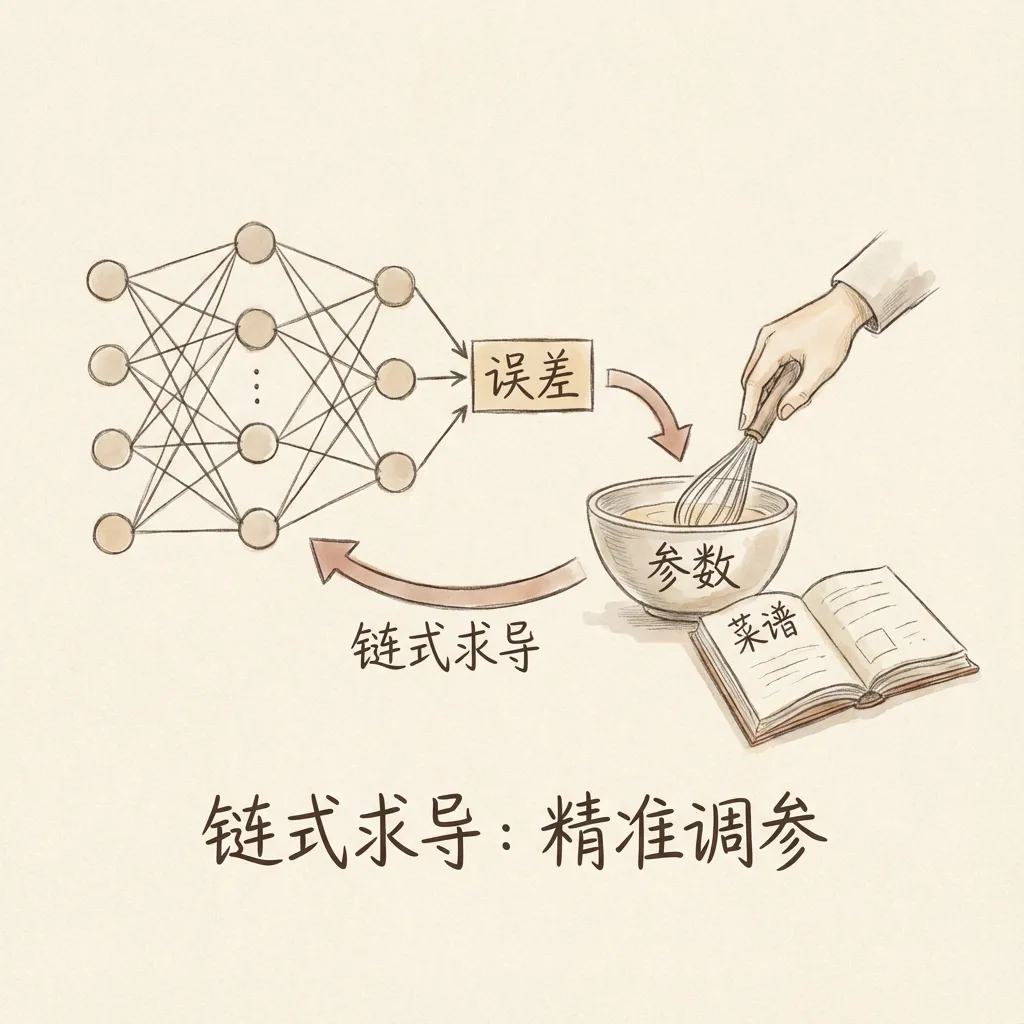
4.5 什么是反向传播
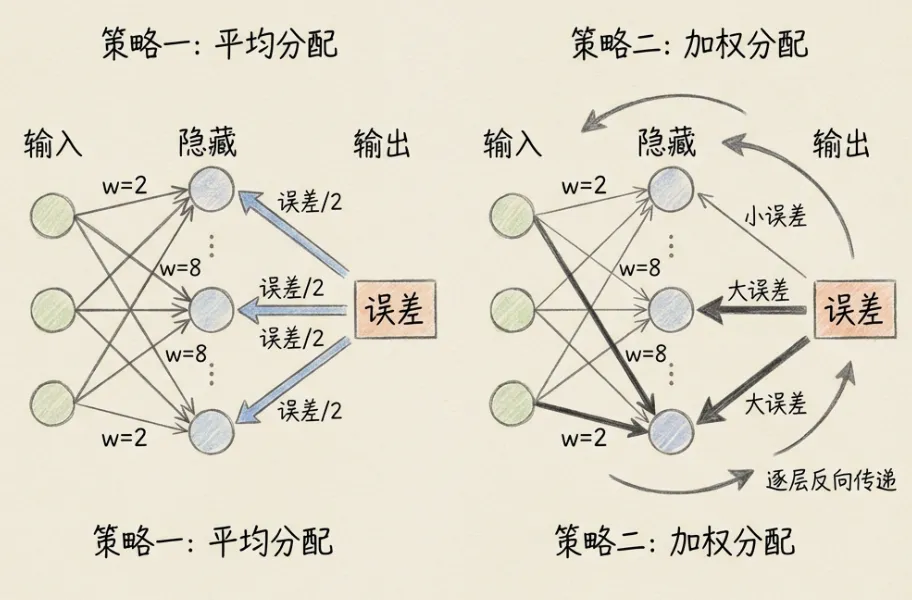
反向传播从输出层朝着输入层的方向逐层传递误差,将误差”分摊”到每个神经元。就如同成本不合格时,逆向地逐层落实责任。
4.6 反向传播在传播什么
反向传播的目的是解决误差在各层神经元间的”摊派”问题,确定每个神经元应该承担多少责任。
4.7 权重更新策略
神经元需要根据分摊到的误差来调整权重,使下次预测更接近目标值。
4.8 链式求导与连续性
1986年辛顿等人发表的论文,提出将链式求导法则应用在神经网络参数更新上,使参数更新有了精确可计算的数学依据。
链式求导的前提是要求函数是连续的。这也就是阶跃函数后来被Sigmoid函数替代的根本原因——阶跃函数是不连续的函数,没办法应用链式求导法则。
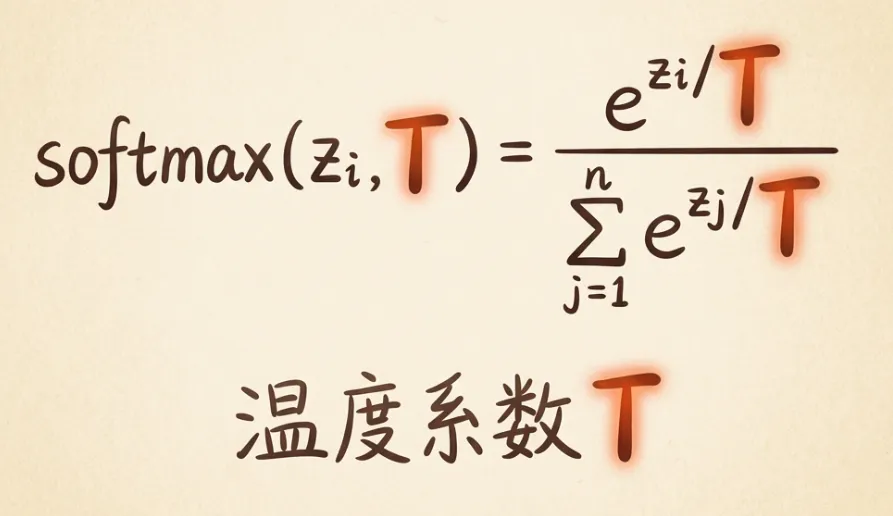
4.9 梯度下降
梯度下降是按照”指南针”(偏导数)来确认参数更新变化量的方法:
- 链式求导计算出偏导数,确定参数更新方向
- 梯度下降按照负梯度方向小步调整,使损失函数值持续下降
参数更新公式:
Δθ = −η⋅∇θL其中:η是学习率,∇θL是损失函数梯度。
5. 初识大语言模型
5.1 大语言模型与神经网络
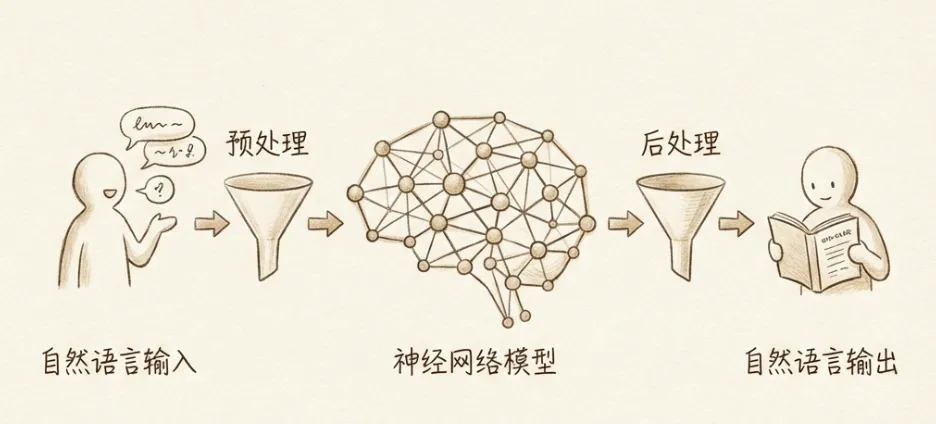
大语言模型是专门处理自然语言的神经网络模型。它需要:
- 在自然语言输入神经网络之前,进行预处理
- 在神经网络输出后,转换为人类可读的自然语言
5.2 TOKEN、分词
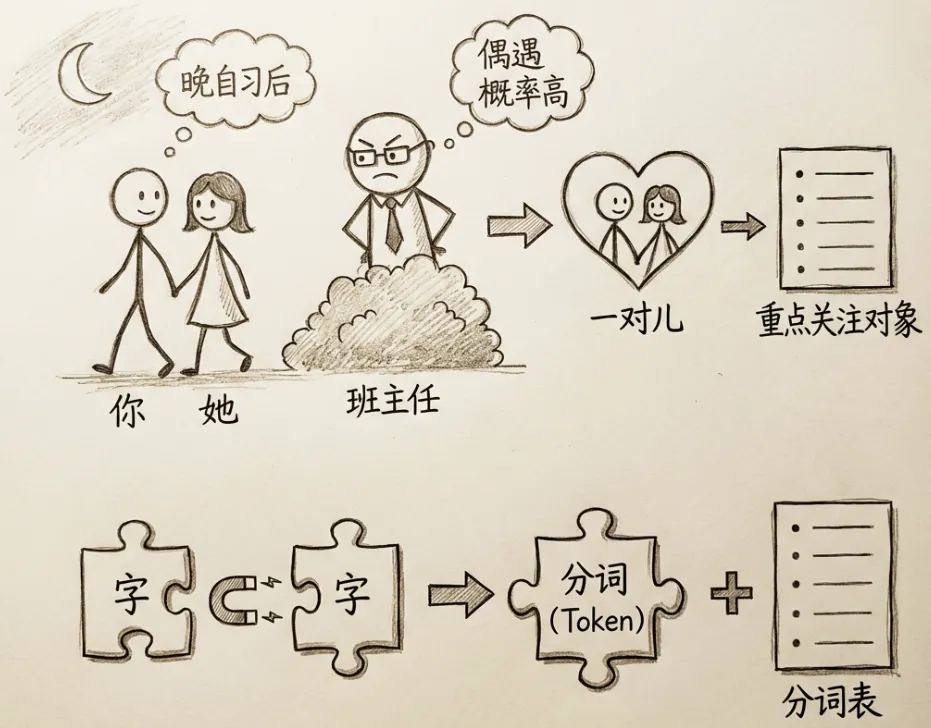
大语言模型对输入的句子或段落先要进行”断句”,称为分词。例如”我爱吃香蕉”会被拆分成:我 | 爱 | 吃 | 香蕉。
分词的目标是将文本拆解为语义紧密关联、且具备独立意义的最小语言单元。常用的算法是BPE(Byte Pair Encoding),如果某两个字经常挨在一起,就会被组合在一起,成为分词。

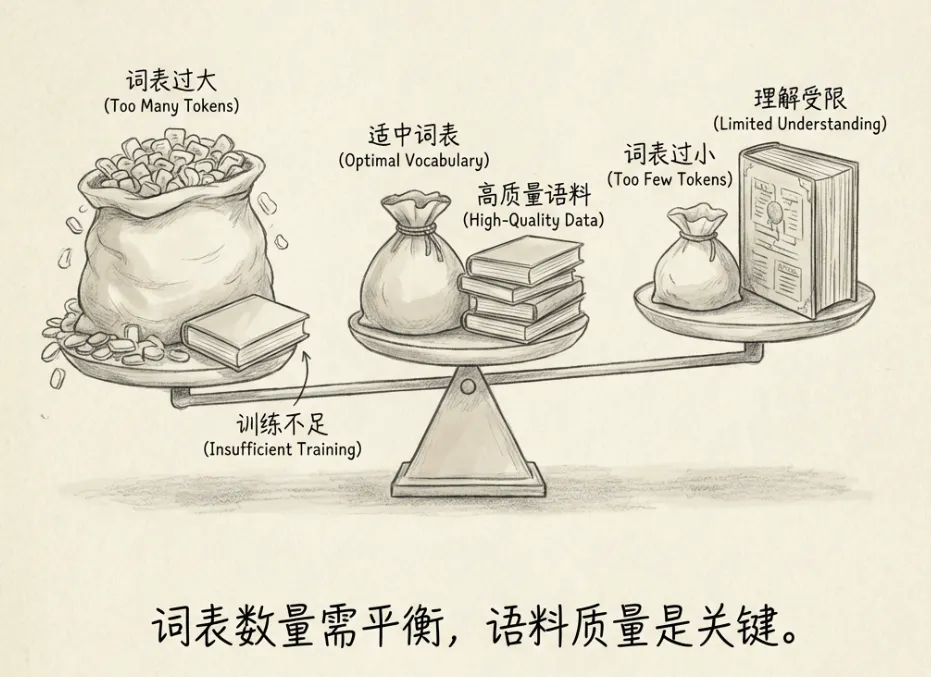
5.3 词表与词表大小
预先拆分好的Token会被记录在词表中。模型的理解能力完全取决于其对词表中Token语义的理解。
词表大小需要平衡:
- 词表太少:表达能力不足
- 词表太多:训练不充分
5.4 向量化和词嵌入
Token在进入大模型之前需要被转换为多维向量,这个过程称为向量化。
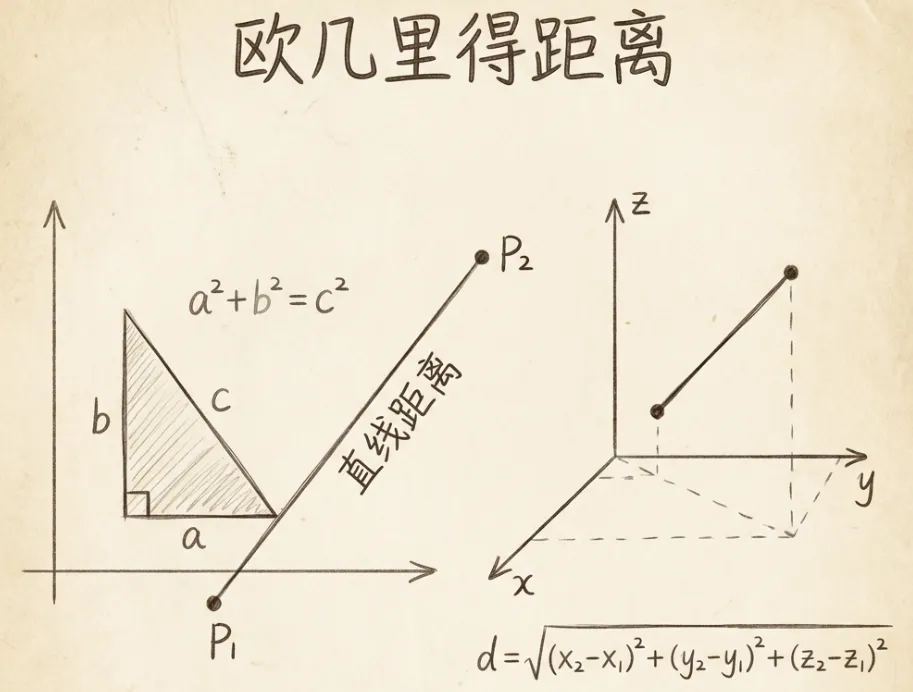
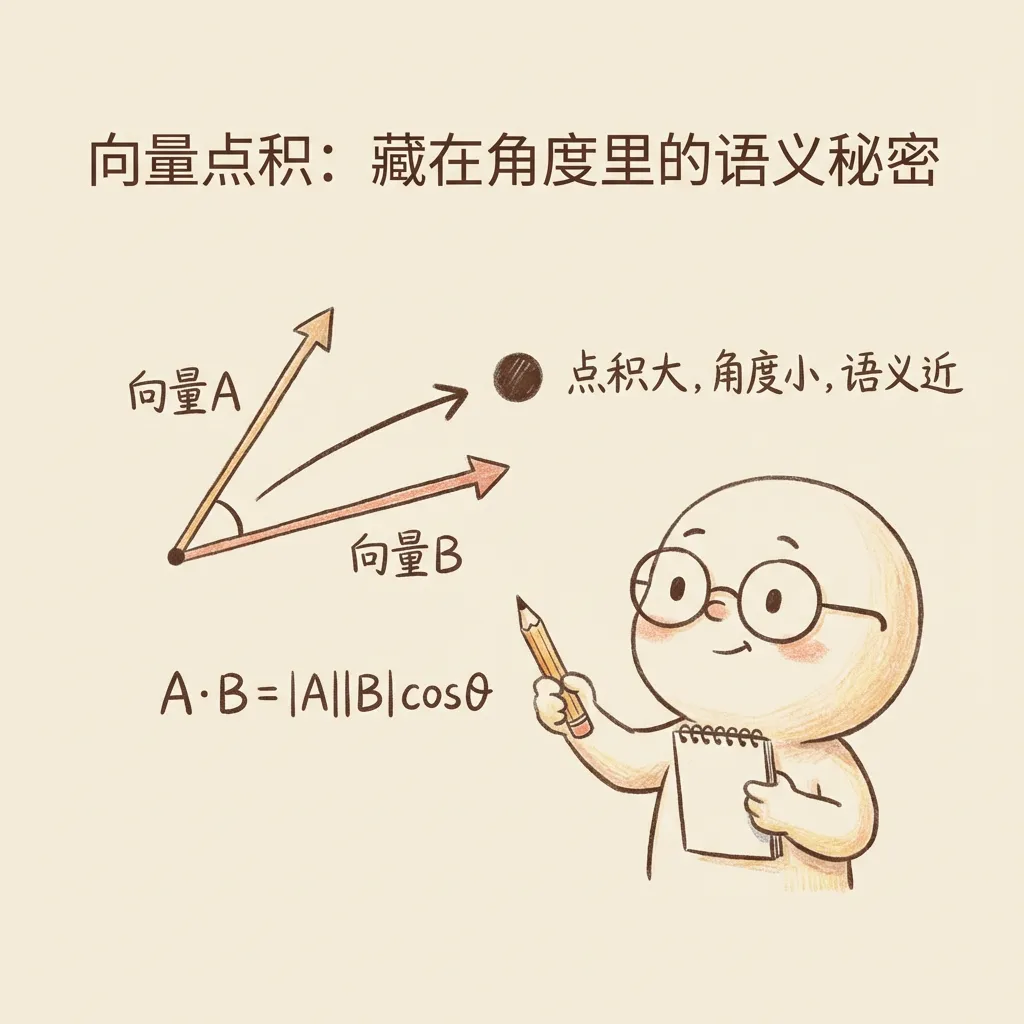
用多维向量表示token的过程称为词嵌入。向量之间的”距离”和”夹角”可以表示语义的亲疏远近:
- 欧几里得距离:表示向量之间的距离
- 向量点积:夹角越小,语义越相近
5.5 大模型的输出
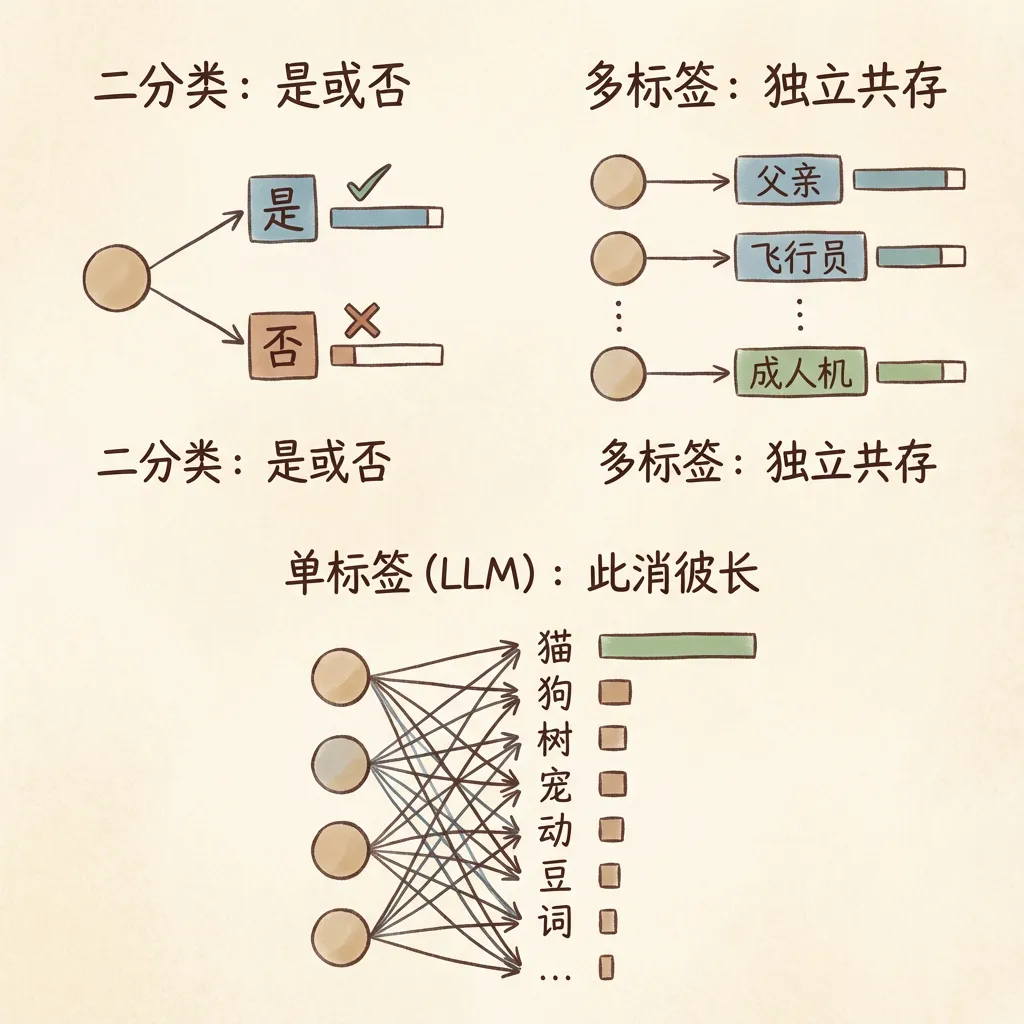
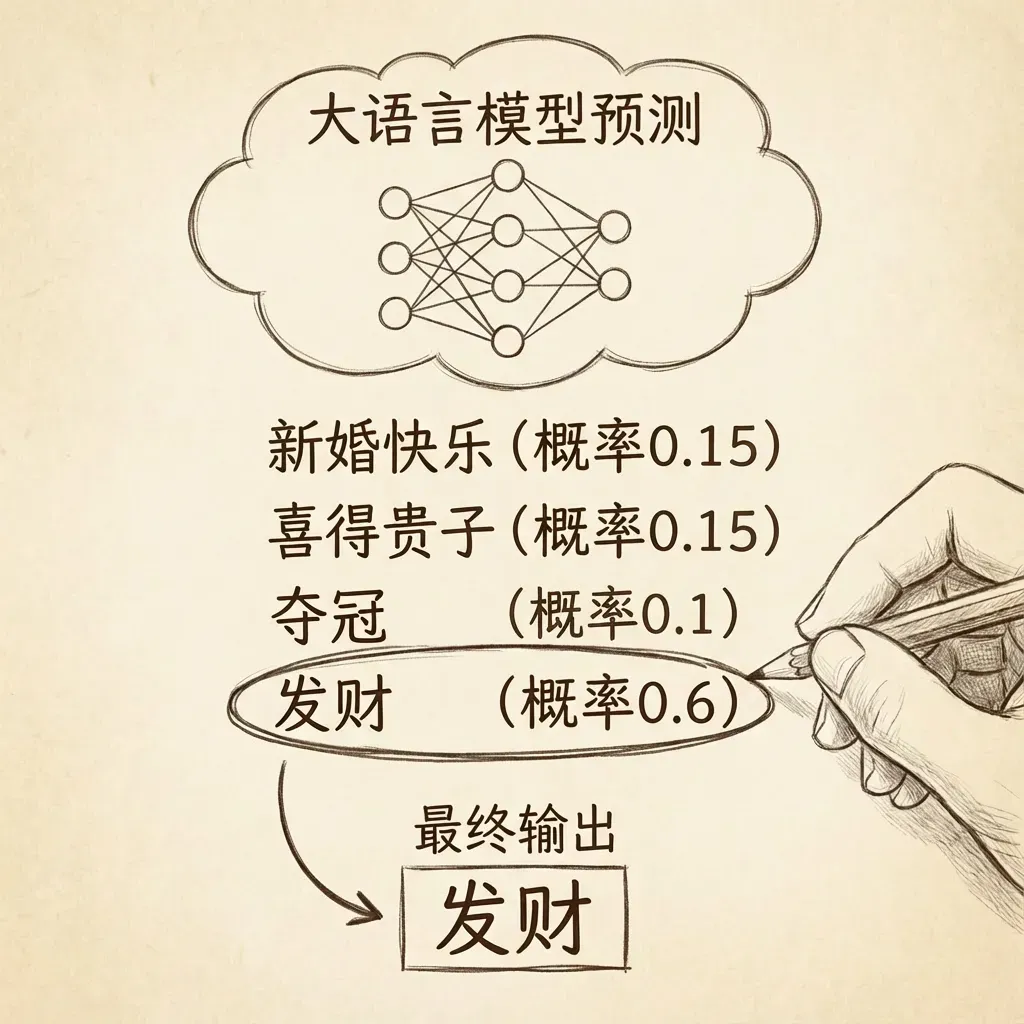
神经网络的输出是对整个词表中所有token的预测概率。大语言模型会挑选概率最高的分词作为最终输出。
例如输入”恭喜”,可能输出:
- 新婚快乐(概率0.1)
- 喜得贵子(概率0.1)
- 夺冠(概率0.01)
- 发财(概率0.6)
5.6 Softmax与概率预测
Softmax函数将神经网络的输出数值归一化,使所有概率总和为1,实现”此消彼长”的概率分布。
5.7 概率与Token映射
词表中的token会有对应的索引(id)。输出的概率列表中,最高概率对应词表中相应id的token。
5.8 单标签与多分类
大语言模型的输出层神经元数量等于词表大小,属于多分类任务。不同概率之间有”此消彼长”的关系,称为单标签。
6. 我的昨天在消失,明天不可知
6.1 上下文
上下文是大模型理解语言的关键能力。没有记忆的大模型只能捕获最后一个字,忽略整个语境。上下文长度决定了模型能关注到周围多少个分词。
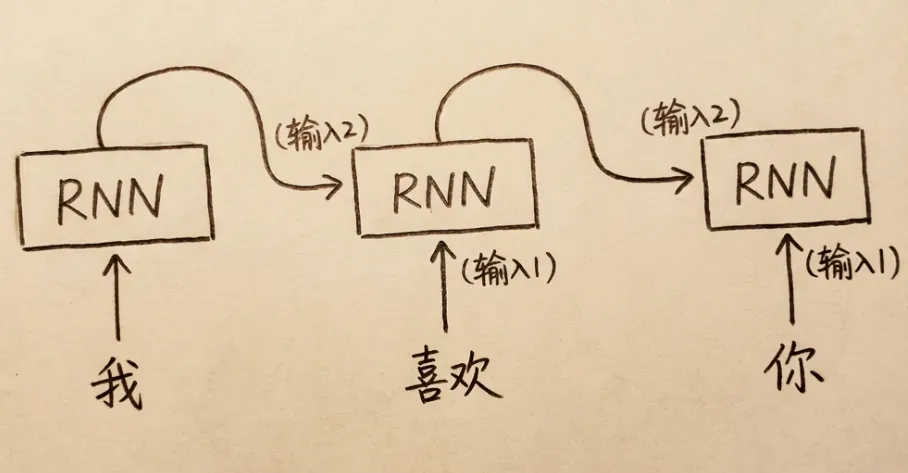
6.2 循环神经网络(RNN)
循环神经网络的输出会同时作为输入,再次”回环”输入到神经网络。每次循环,神经网络都会同时接收:
- 上次循环的输出(隐藏状态)
- 下一个分词的token
RNN的短板是串行执行带来的性能不足,无法进行分布式并行计算。

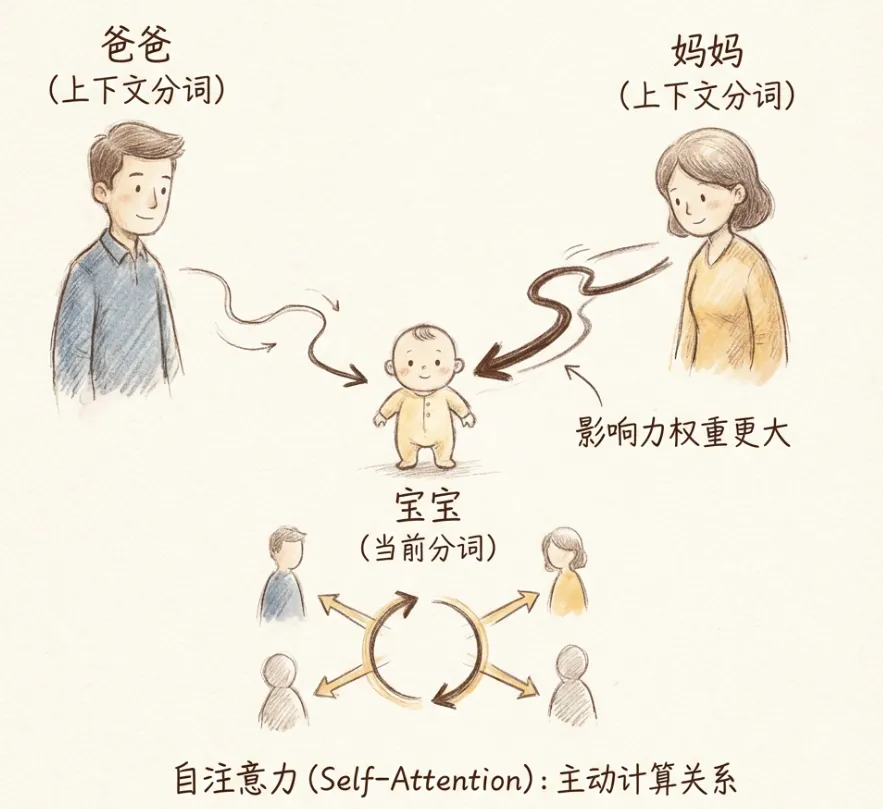
6.3 自注意力与Transformer
2017年Google发表的《Attention Is All You Need》论文,提出了Transformer架构,基于自注意力机制。
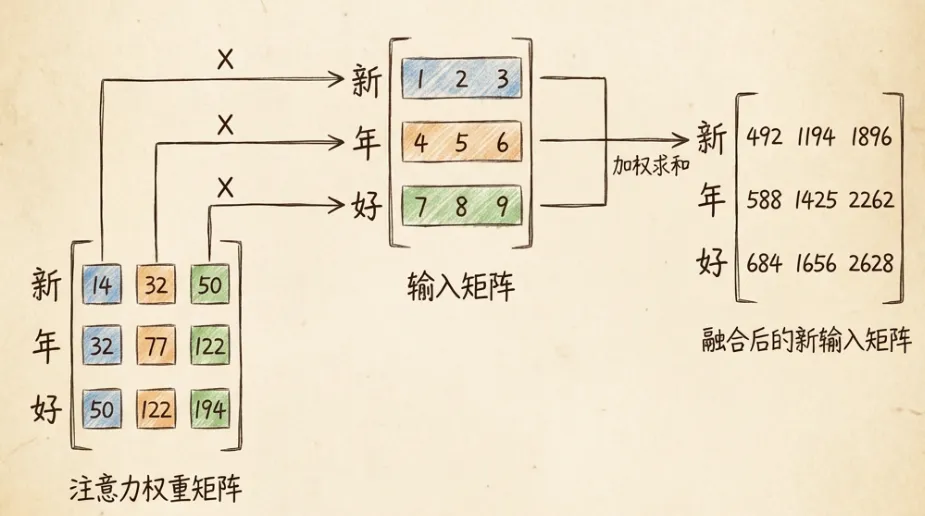
自注意力机制:
- 每个分词与其他分词逐个计算”注意力权重”
- 基于权重融合生成当前分词的自注意力词向量
Transformer既具备”融合上下文”的能力,又解决了RNN串行计算的的性能问题。由于自注意力本质上是矩阵乘法,可以进行并行计算。
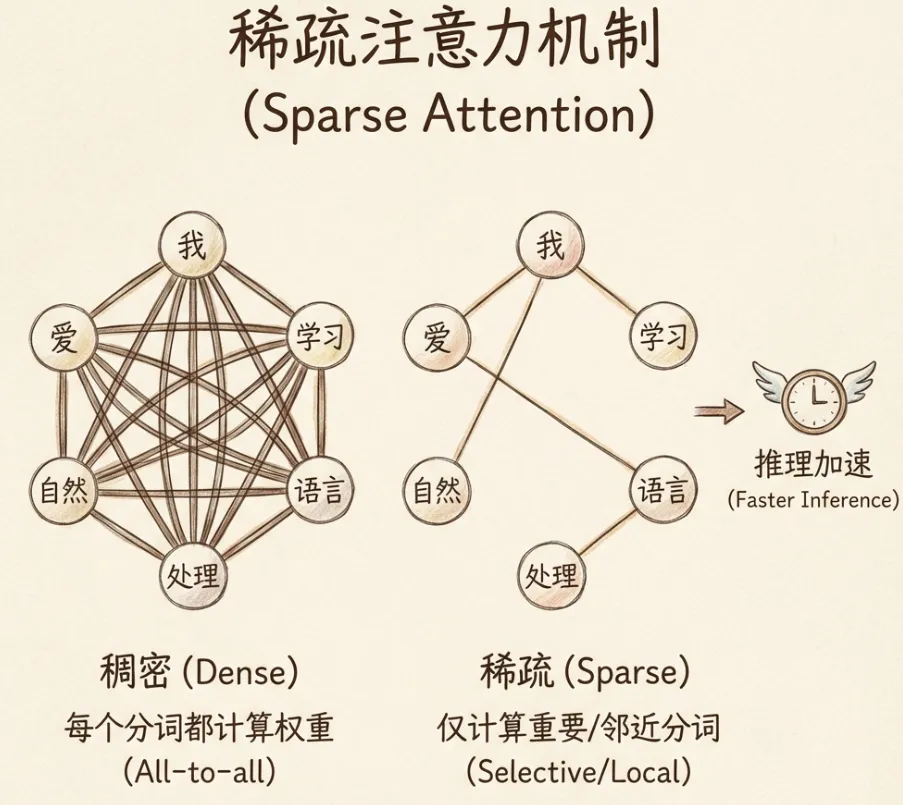
6.4 稀疏自注意力
稀疏注意力机制认为每个分词只需要计算相对重要的分词即可,不必计算所有分词的权重。这减少了计算量,加快了推理速度。
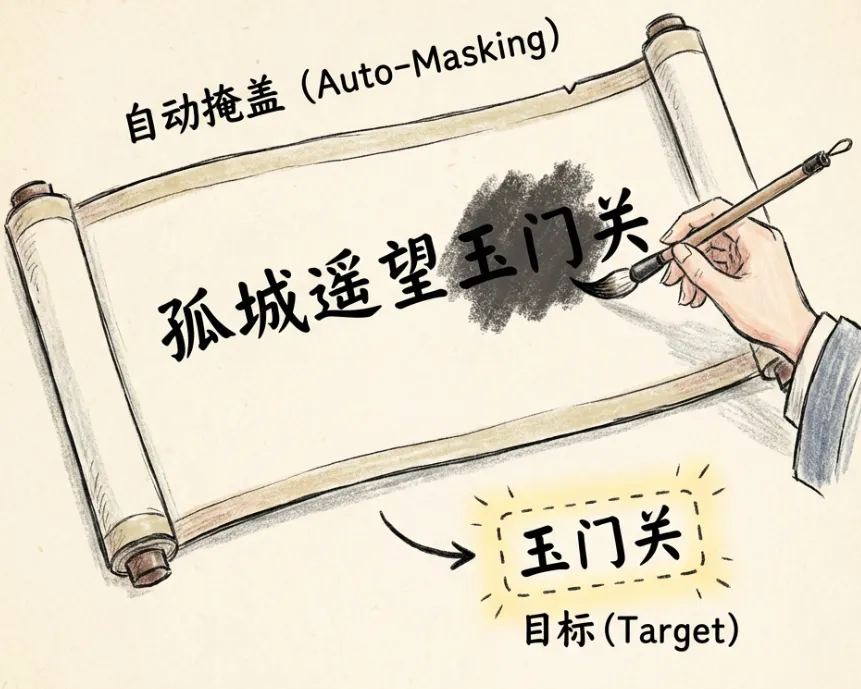
7. 大模型是怎么训练的
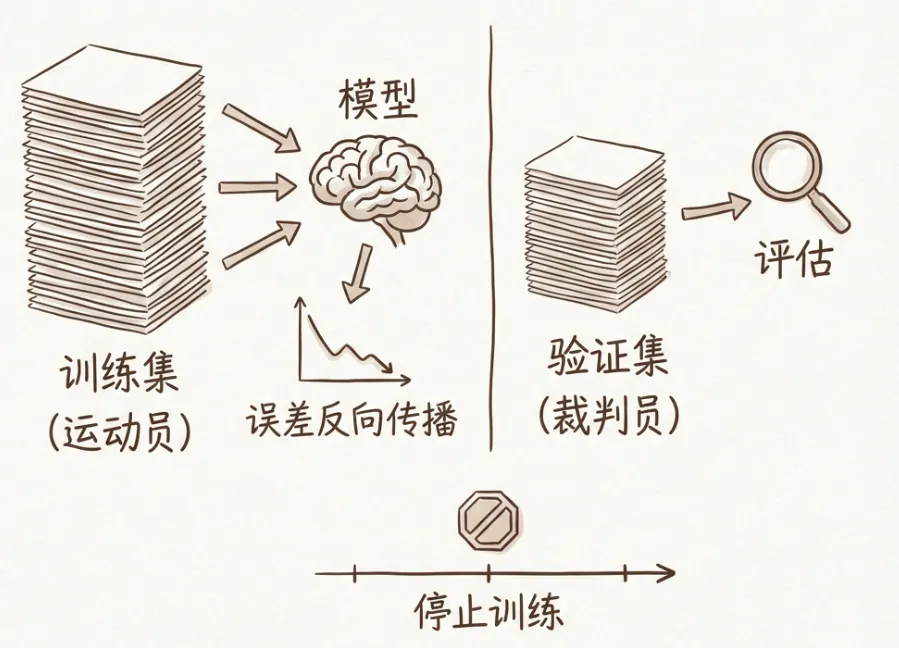
7.1 训练数据
训练数据分为两类:
- 训练数据:用于模型学习
- 验证数据:用于观测模型推理效果
训练过程:输入训练数据 → 输出预测概率 → 计算误差 → 反向传播更新参数。
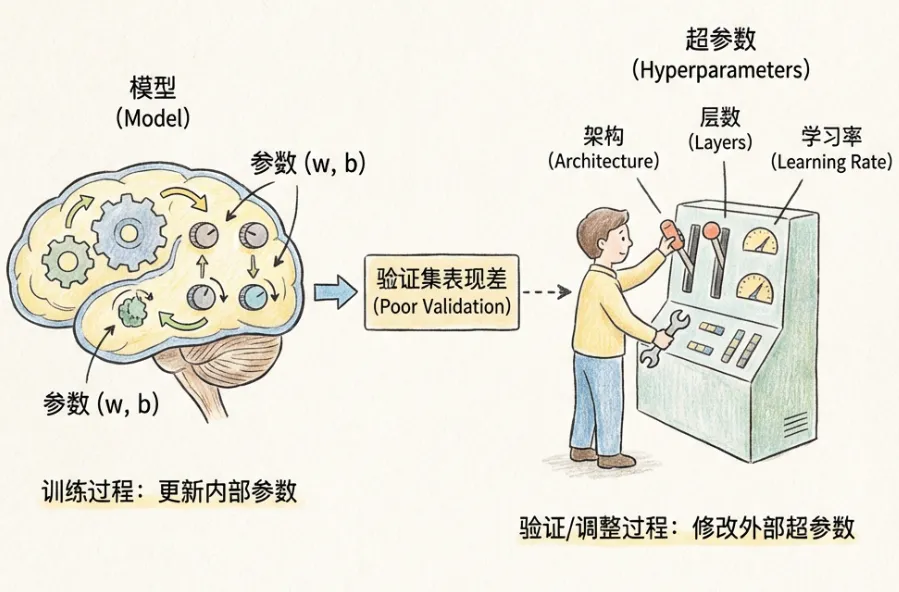
7.2 超参数
超参数是超越模型自身参数以外的参数,包括:
- 模型架构
- 神经网络层数
- 学习率
7.3 批量(Batch)
大模型训练时,把”一堆儿”训练语料一次性输入进去训练,称为批量。
7.4 步长(Step)
将整个批量的误差统一计算平均值,利用平均误差更新模型参数。每一次参数更新称为一个步长或迭代。
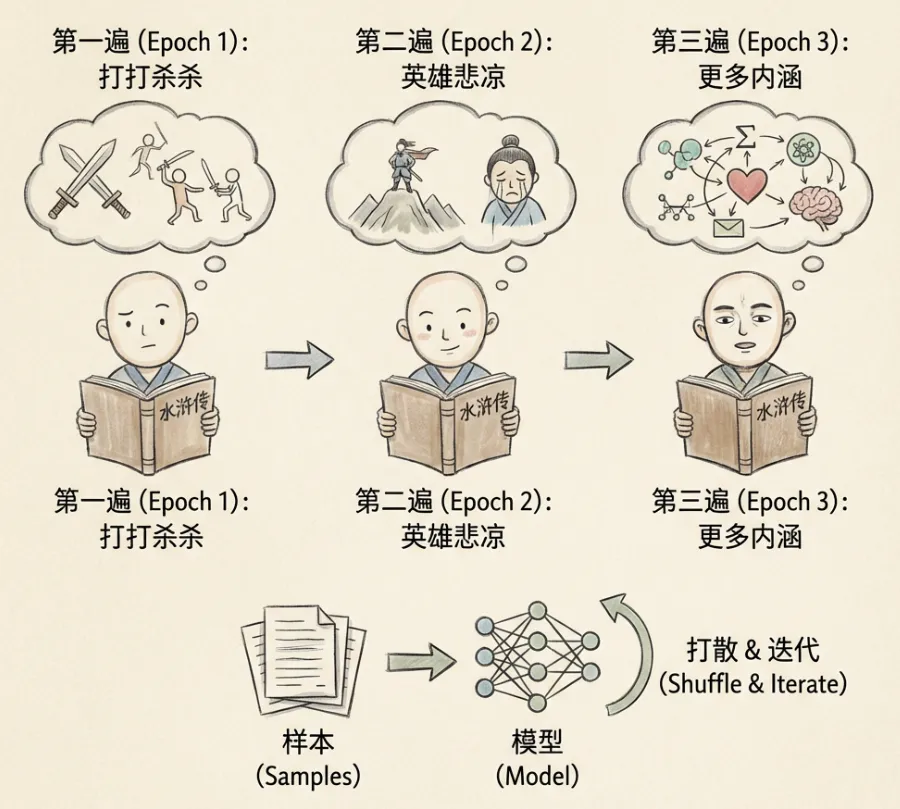
7.5 训练轮次(Epoch)
模型完整遍历一次数据的过程,称为一个轮次。训练需要多轮迭代。
7.6 过拟合与欠拟合
- 欠拟合:经过多轮训练后,误差仍然很大,可能是模型参数量太少
- 过拟合:训练数据误差小,但测试数据误差大,模型”死记硬背”,泛化能力不足

7.7 监督学习和自监督学习
- 监督学习:目标值需要人工标注
- 自监督学习:自动选取目标值,如随机掩盖句子中的分词,让模型预测被掩盖的分词
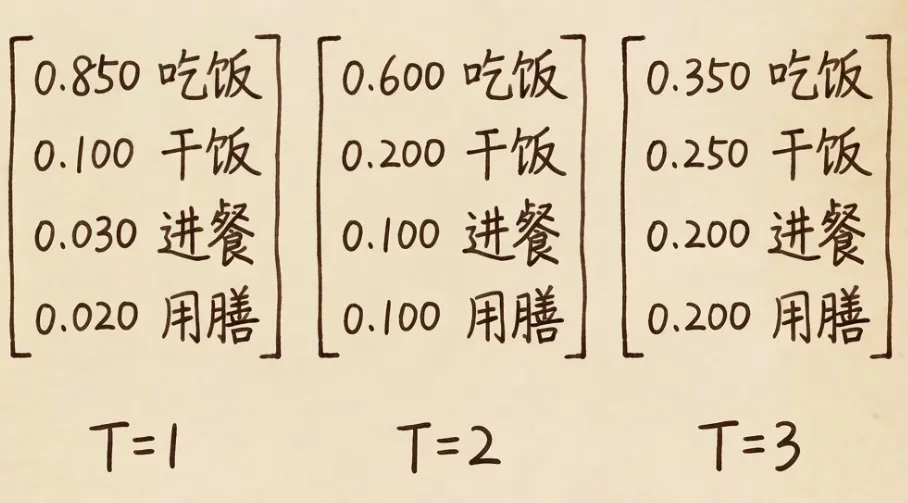
7.8 温度系数
温度系数控制概率分布的”热胀冷缩”:
- 温度低:概率高的更高,概率低的更低(冷缩)
- 温度高:概率分布更均匀(热胀)

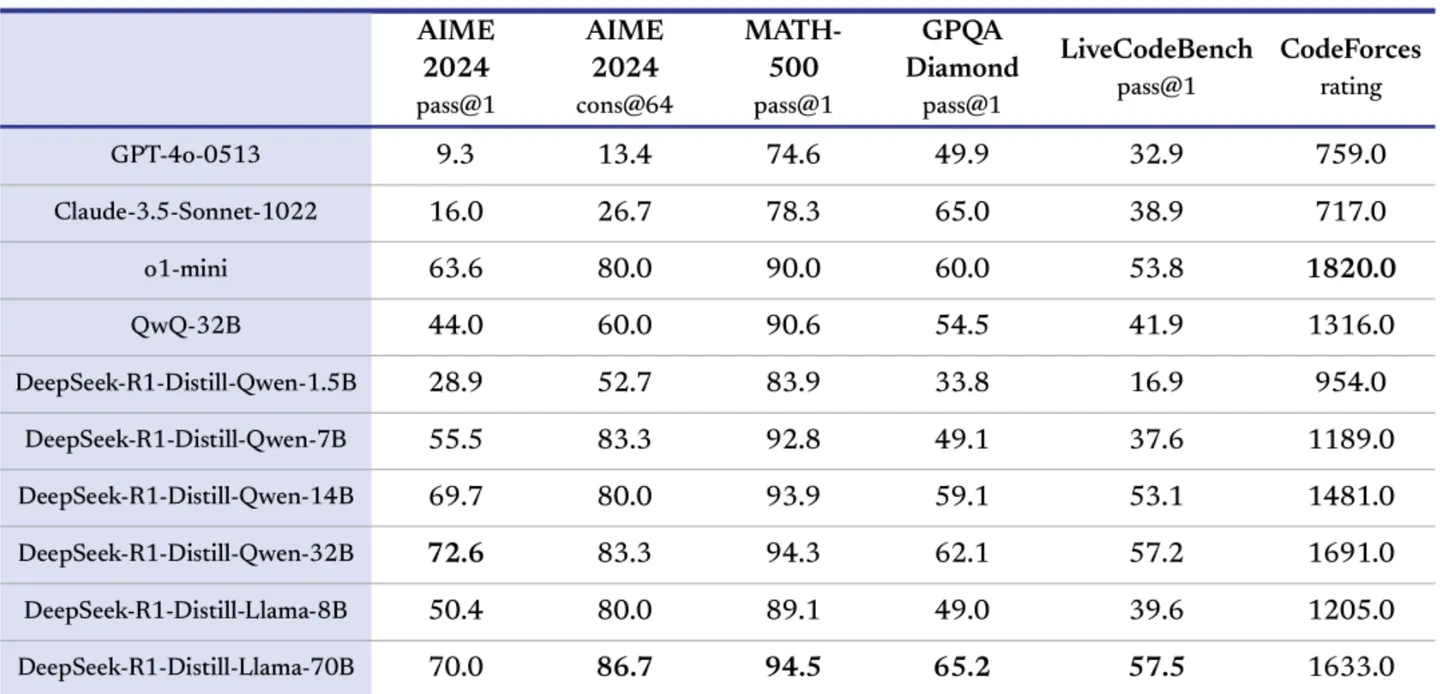
7.9 蒸馏学习
蒸馏学习:学生模型向老师模型学习,用尽可能少的参数达到大模型的能力。DeepSeek-R1 通过蒸馏开源了6个小模型。

8. AI浪潮下的基础设施
8.1 AI与区块链算力
比较了区块链挖矿与AI训练在计算模式上的异同。
8.2 GPU卡与CUDA
一块英伟达GPU H100卡有18000多核,这些核被称为CUDA核。虽然它们数量多,但仅能进行简单的加减乘除计算,对于AI训练和推理已经足够。
CUDA平台提供了一站式的均衡调度能力。
8.3 大模型并行计算
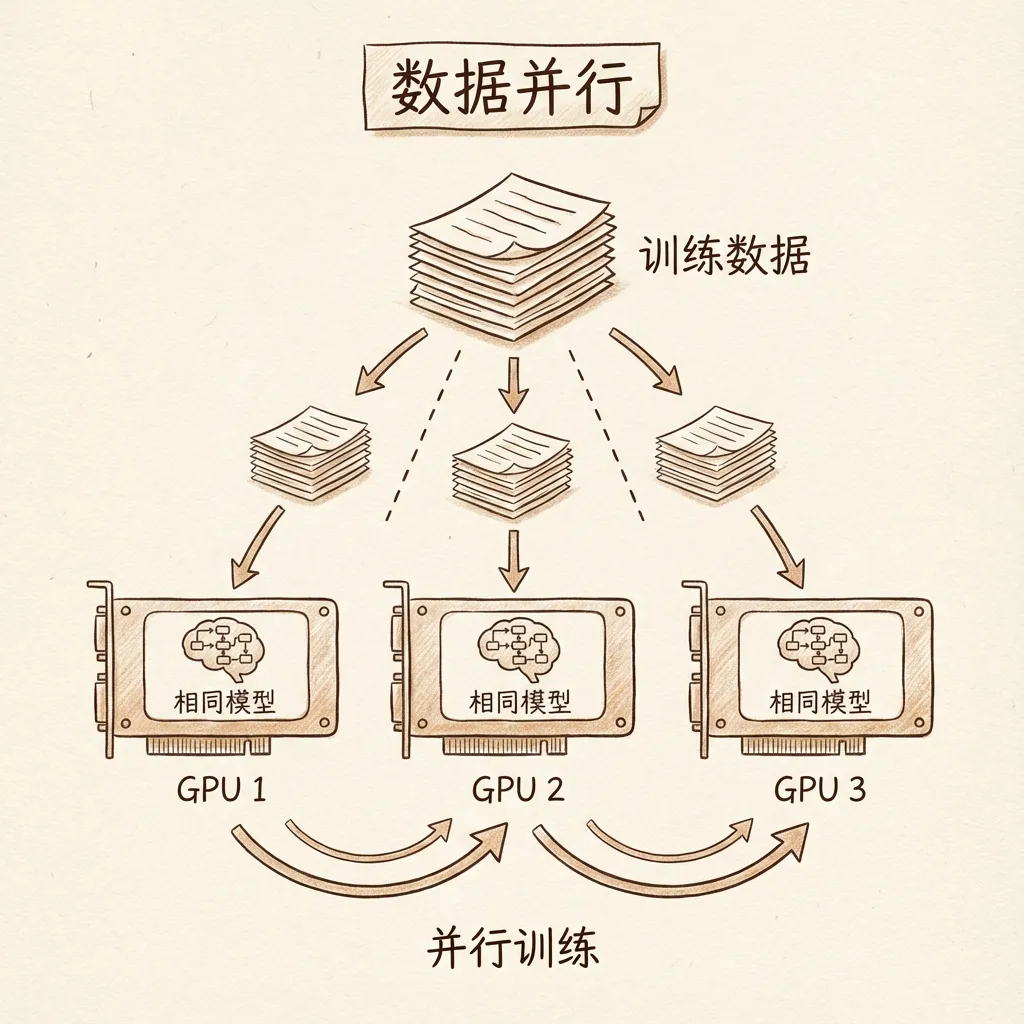
并行计算分为两类:
- 模型并行(张量并行):把参数分布在不同GPU上计算
- 数据并行:把训练数据分散到不同GPU上,每个GPU运行相同的模型
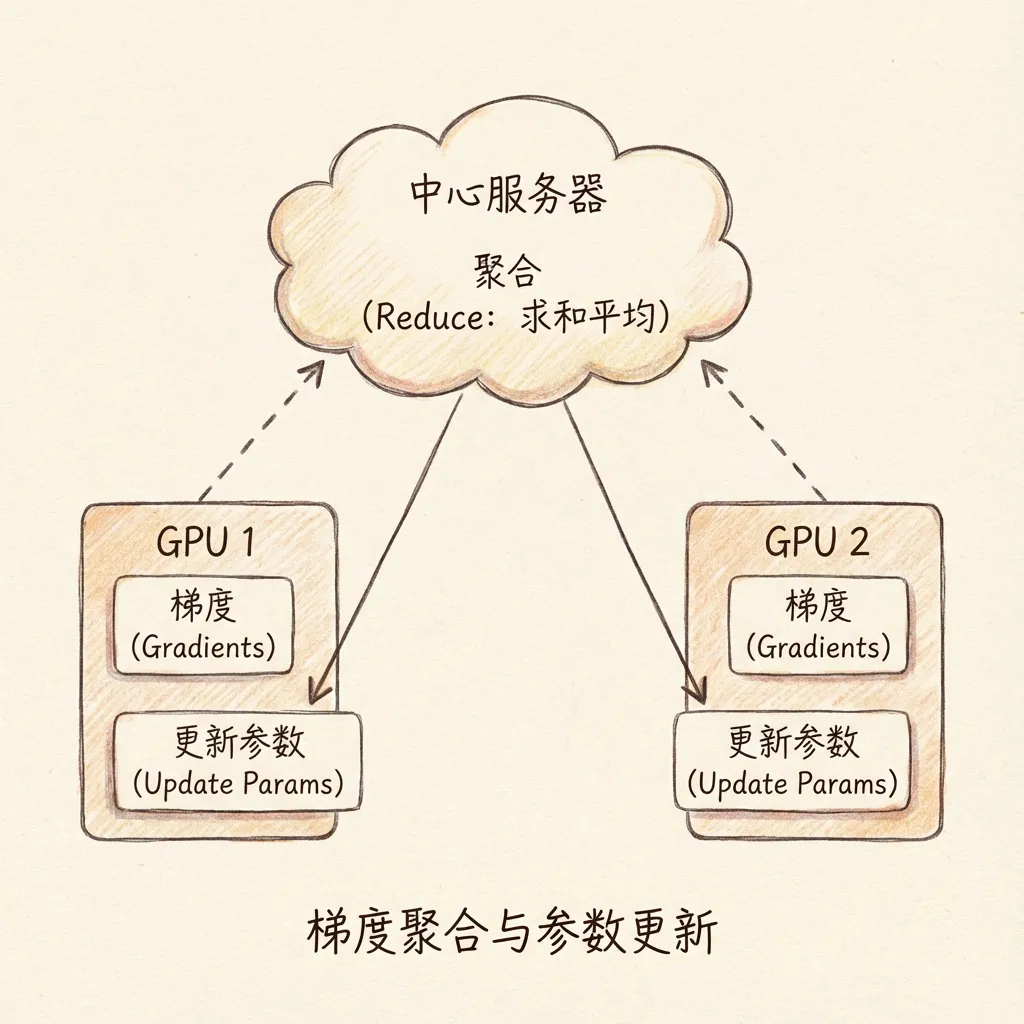
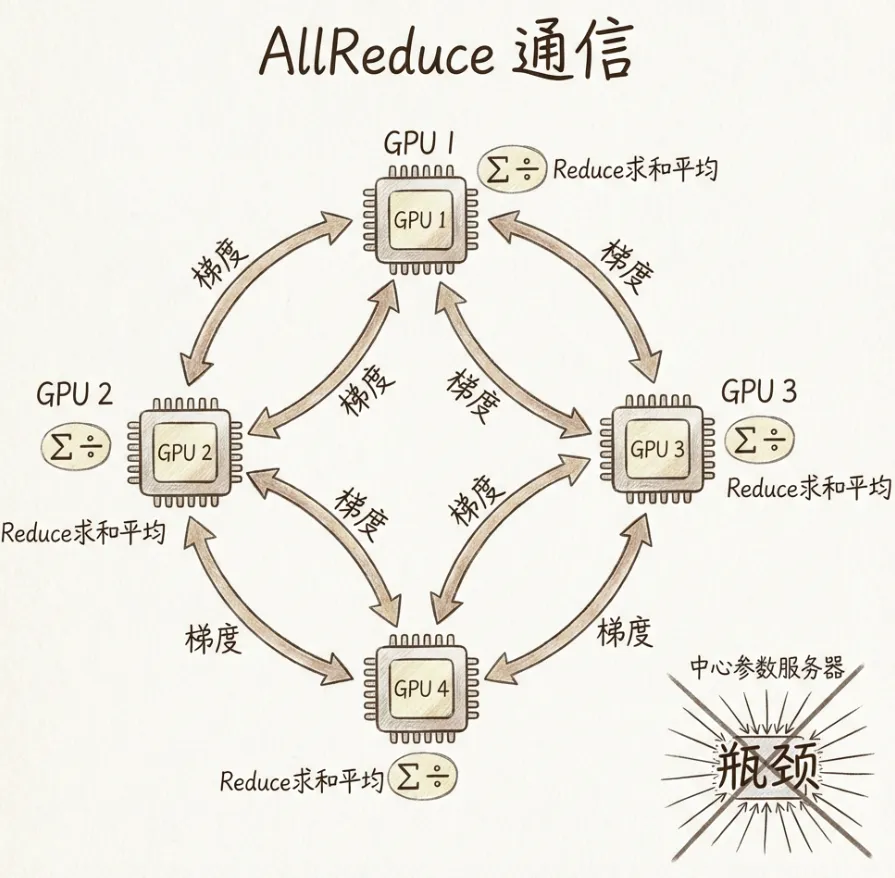
8.4 数据并行
详细说明了数据并行下,参数服务器或AllReduce通信模式如何聚合梯度并更新参数。
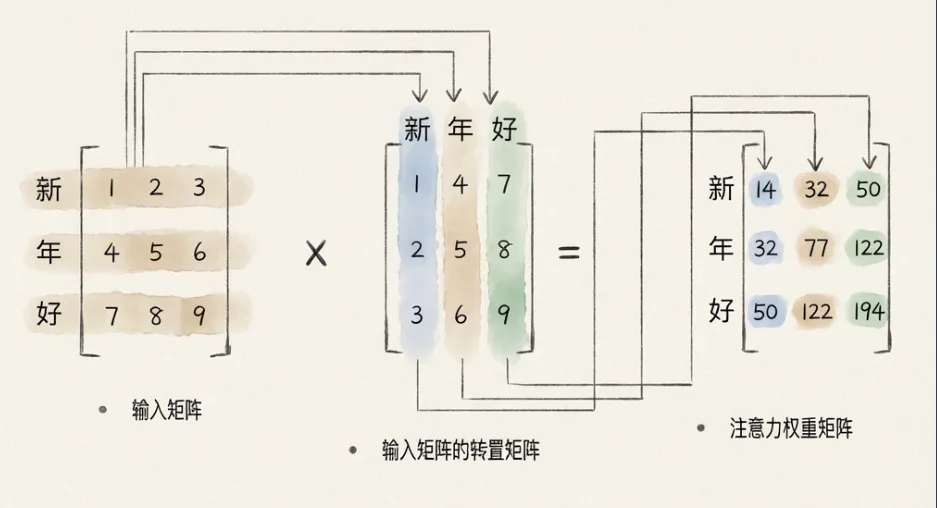
8.5 模型并行
通过图示解释了如何将神经网络矩阵运算拆分到多块GPU上。
8.6 NCCL集合通信
NCCL是英伟达提供的通信库接口,开发人员调用 allgather()、allreduce() 等函数完成GPU间通信。
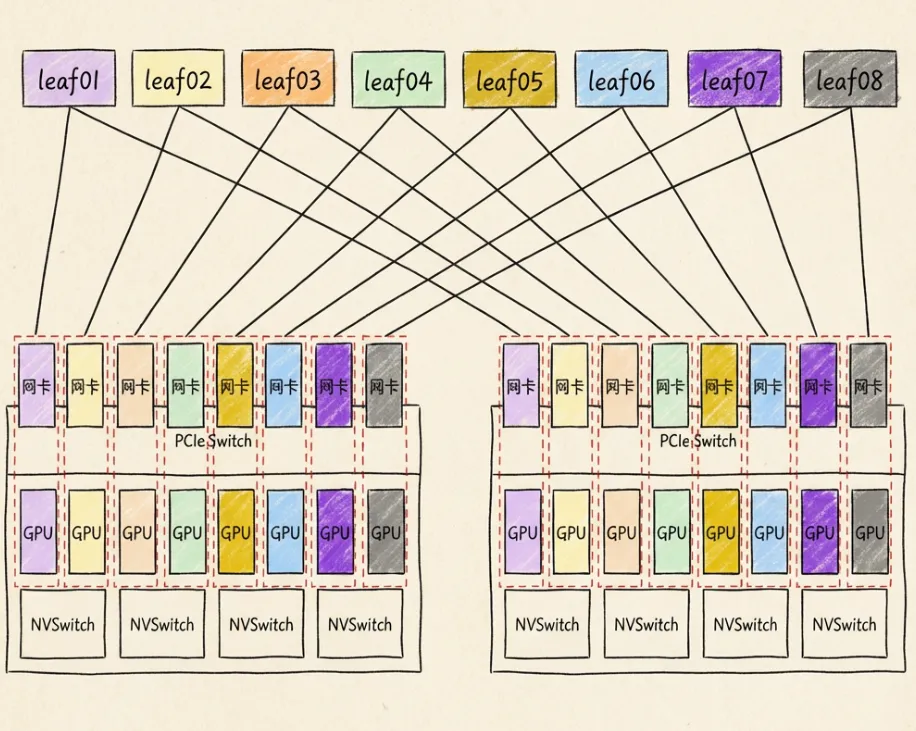
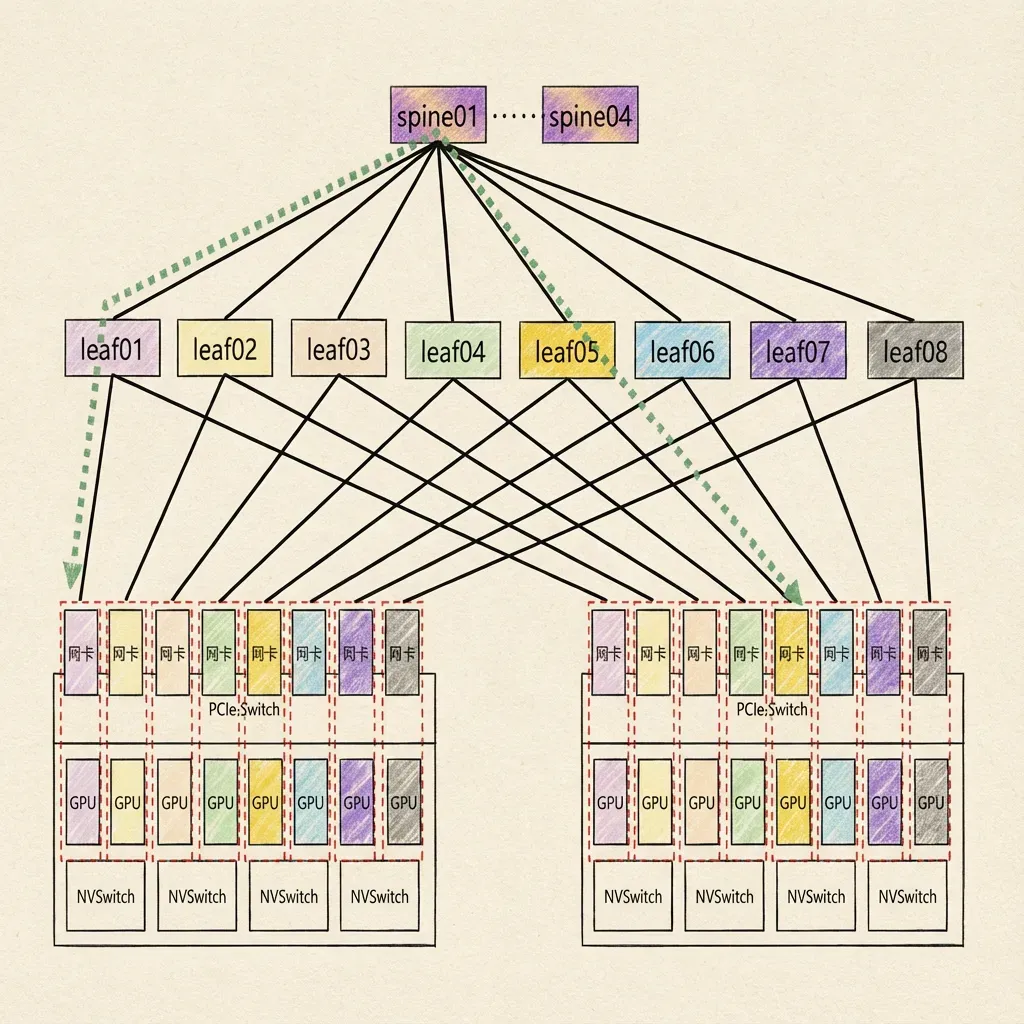
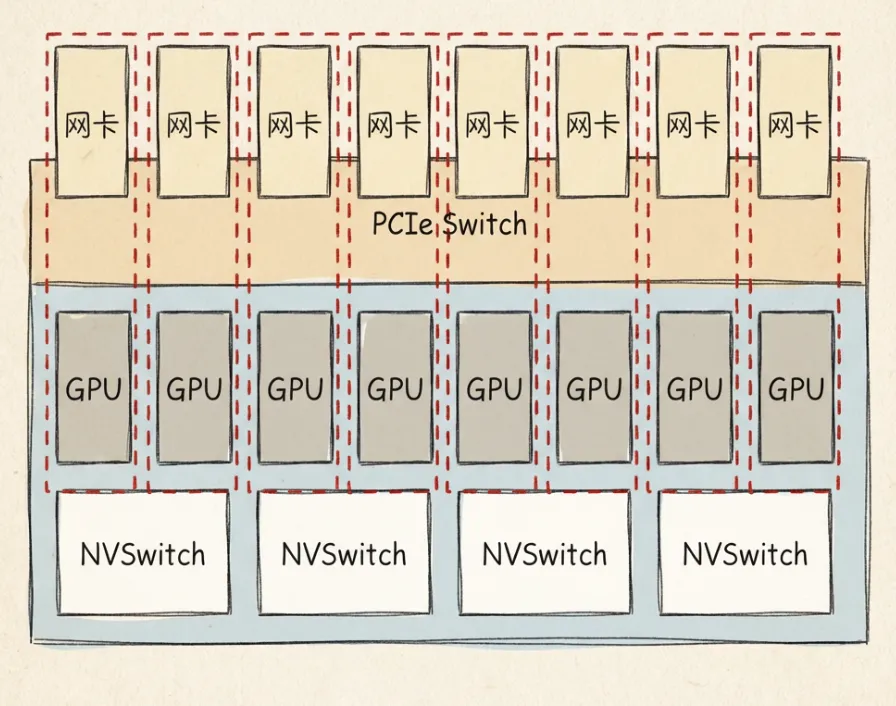
8.7 GPU服务器内通信
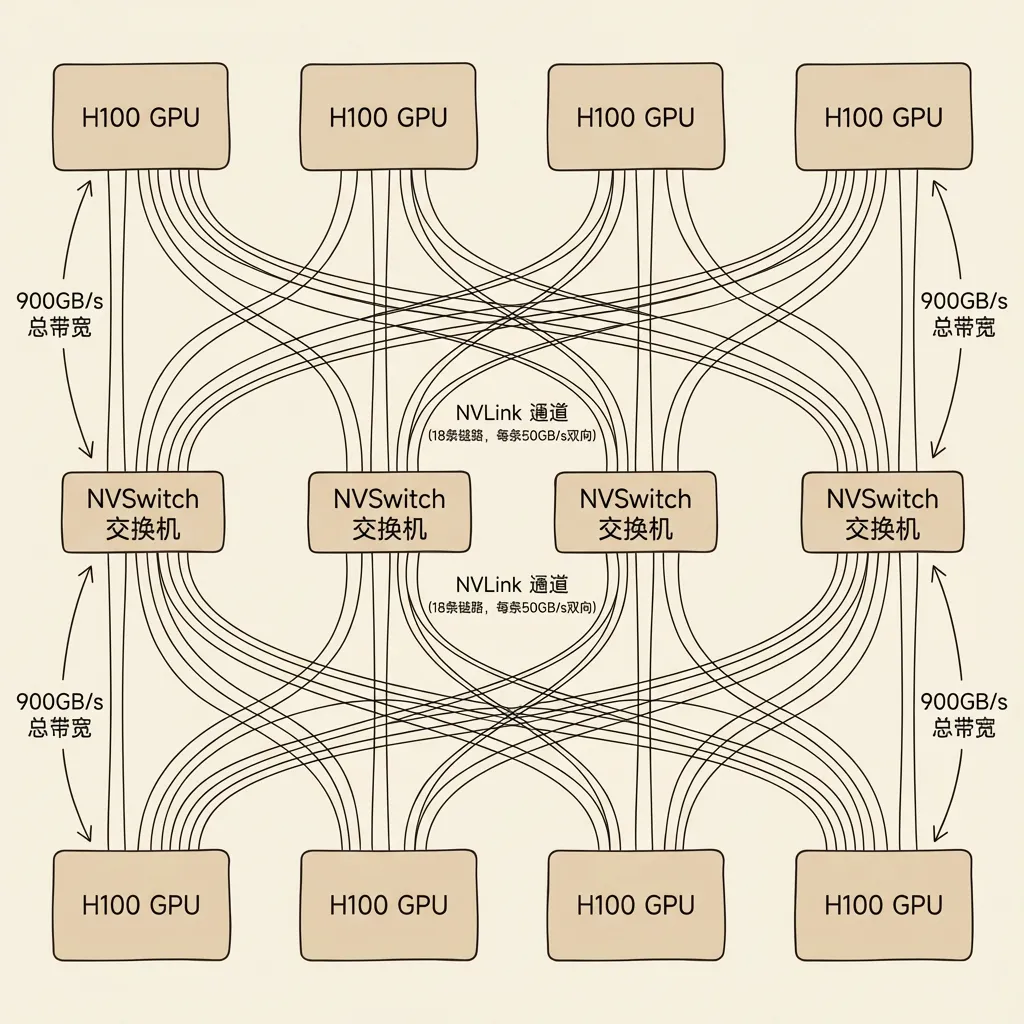
H100整机集成8块GPU,每两块GPU之间通过NVLink互联,带宽高达900GB/s。GPU接入NVSwitch交换机,采用4平面设计。
8.8 GPU服务器间通信
跨服务器通信依赖物理网络。GPU网卡采用ConnectX系列:
- A100:ConnectX-6,端口速率200Gbps
- H100:ConnectX-7,端口速率400Gbps
9. 大模型的使用
9.1 大模型的不足
- 知识陈旧:模型训练好后参数固定,无法实时更新动态数据(天气、股价、新闻等)
- 幻觉:概率模型导致回答不准确、答非所问
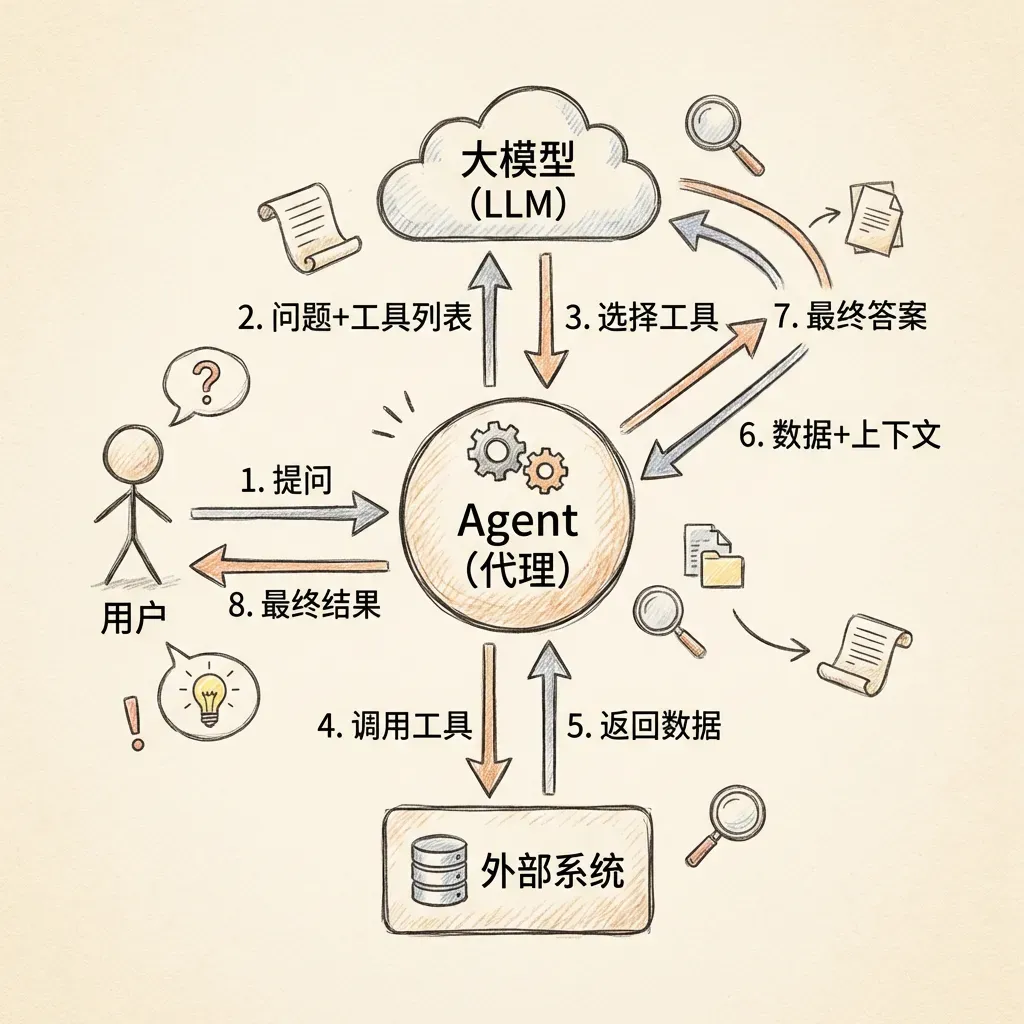
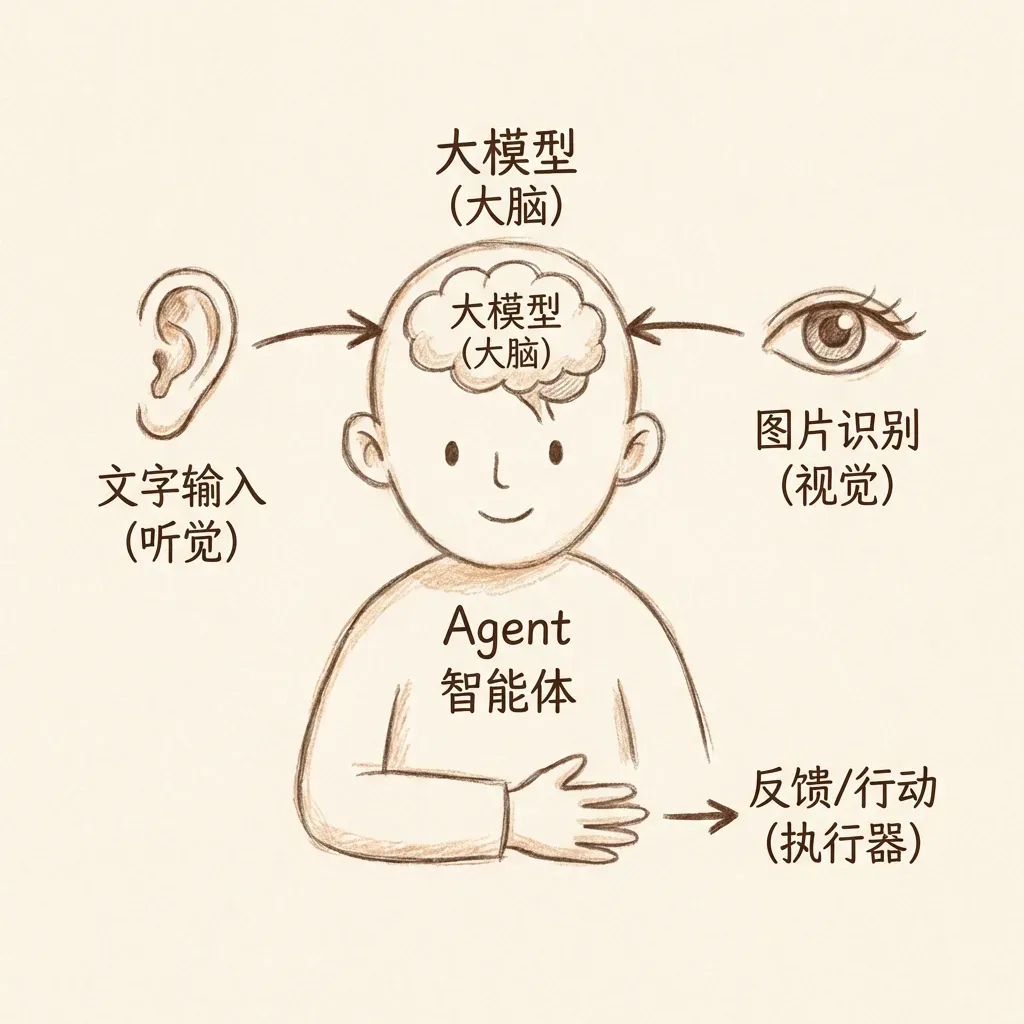
9.2 Agent
Agent智能体能够对外部环境进行感知、思考决策,并且具有执行能力。Agent至少要具备感知器和执行器两个组件,大模型相当于大脑。

9.3 MCP
MCP(模型上下文协议)定义了Agent与外部系统间交互时的通信标准。Agent可以通过MCP从外部系统获取动态数据。2025年12月,MCP捐赠给Linux基金会,成为行业标准。
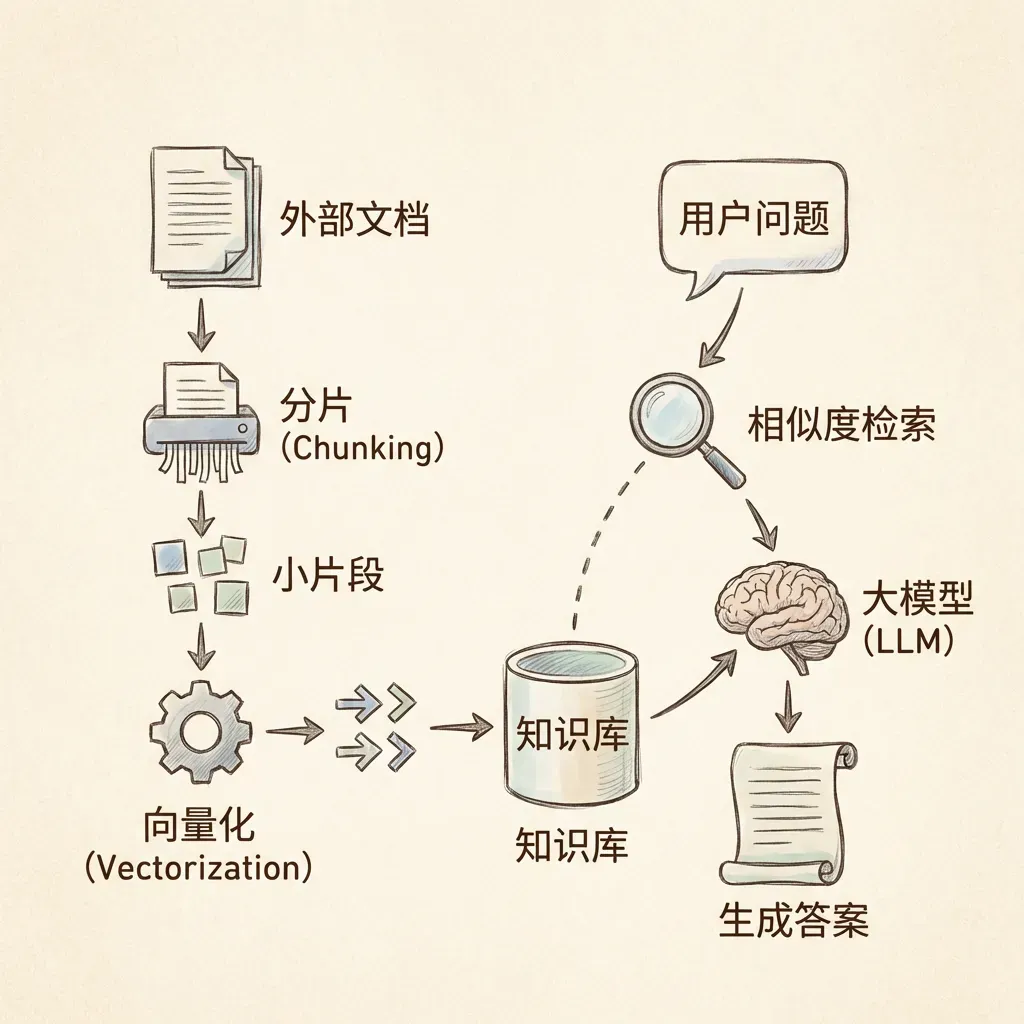
9.4 RAG
RAG(检索增强生成)是大模型的外部”知识库”。核心工作机制:
- 对外部知识文档进行分片处理
- 将分片内容转化为向量
- 匹配高相关度的知识分片
- 与用户问题整合,输入大模型生成答案
9.5 A2A
A2A协议是不同Agent之间通信的标准协议,由Google于2025年4月发布,捐赠给Linux基金会托管。
10. 结尾
2025年岁末,神经网络经过几十年的沉寂,终于迎来春天。时过境迁,人们对于神经网络的悲观情绪早已一扫而光。就在此时此刻,它正经历着属于它的时刻。
正如李飞飞所说:人工智能算法不是像传统算法那样,被告知该做什么,而是通过数据来学习该做什么。
参考资料
- 原文链接:https://zhuanlan.zhihu.com/p/2000571234996479582
- 作者:白玉光
- 发布日期:2026年1月30日